Introduction
Python and R are the most popular machine learning languages. Jupiter notebooks are the most popular platform for python users to write up and run code. Rmarkdown can also be used for this same purpose. The choice of which of these two largely depends on your goals, interest and background.Those with a background in statistics overwhemly prefer to work in R wheareas those with computer science background prefer python. Which is better? R or Python is often asked. Neither one is beter than the other. A third alternative I believe is using both together. The availability of libraries that allows you to work interchangeably between the two languages has made data science officialy agnostic. Examples of these packages include rPython, PythonInR, reticulate , rJython, SnakeCharmR and XRPython.
Load the required packages.
pacman::p_load(skimr,kableExtra,tidyverse,reticulate,scales,viridis)
The Python Engine
This is a new Python language engine for R Markdown. It supports bi-directional communication between R and Python (R chunks can access Python objects and vice-versa).
import csv
import datetime
import re
import codecs
import requests
import pandas as pd
import random as r
# Importing Dataset
data = pd.read_csv("https://raw.githubusercontent.com/NanaAkwasiAbayieBoateng/Datasets/master/EmployeeAttrition.csv")
# Print Text
print( "working with python" +"in R is much fun")
#generate a random number
## working with pythonin R is much fun
import random as r
print(r.random())
## 0.45130671156685687
print(data[['Age','Attrition','BusinessTravel','DailyRate','Department']].head(3))
## Age Attrition BusinessTravel DailyRate Department
## 0 41 Yes Travel_Rarely 1102 Sales
## 1 49 No Travel_Frequently 279 Research & Development
## 2 37 Yes Travel_Rarely 1373 Research & Development
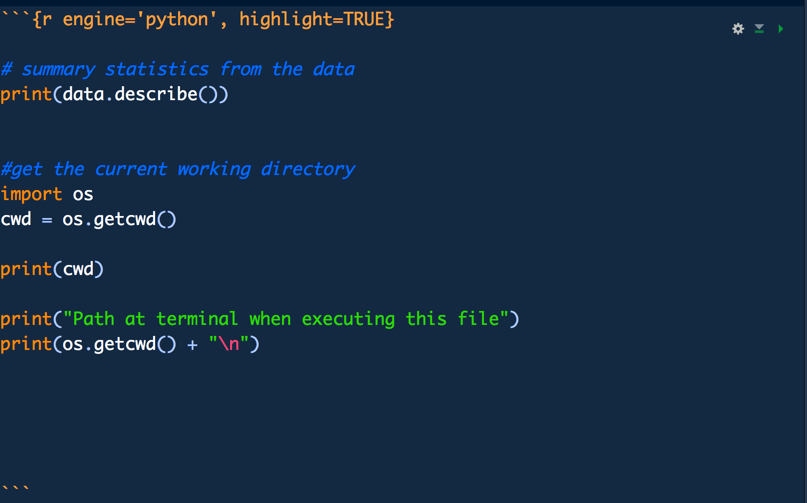
# summary statistics from the data
print(data.describe())
#get the current working directory
## Age DailyRate DistanceFromHome Education EmployeeCount \
## count 1470.000000 1470.000000 1470.000000 1470.000000 1470.0
## mean 36.923810 802.485714 9.192517 2.912925 1.0
## std 9.135373 403.509100 8.106864 1.024165 0.0
## min 18.000000 102.000000 1.000000 1.000000 1.0
## 25% 30.000000 465.000000 2.000000 2.000000 1.0
## 50% 36.000000 802.000000 7.000000 3.000000 1.0
## 75% 43.000000 1157.000000 14.000000 4.000000 1.0
## max 60.000000 1499.000000 29.000000 5.000000 1.0
##
## EmployeeNumber EnvironmentSatisfaction HourlyRate JobInvolvement \
## count 1470.000000 1470.000000 1470.000000 1470.000000
## mean 1024.865306 2.721769 65.891156 2.729932
## std 602.024335 1.093082 20.329428 0.711561
## min 1.000000 1.000000 30.000000 1.000000
## 25% 491.250000 2.000000 48.000000 2.000000
## 50% 1020.500000 3.000000 66.000000 3.000000
## 75% 1555.750000 4.000000 83.750000 3.000000
## max 2068.000000 4.000000 100.000000 4.000000
##
## JobLevel ... RelationshipSatisfaction \
## count 1470.000000 ... 1470.000000
## mean 2.063946 ... 2.712245
## std 1.106940 ... 1.081209
## min 1.000000 ... 1.000000
## 25% 1.000000 ... 2.000000
## 50% 2.000000 ... 3.000000
## 75% 3.000000 ... 4.000000
## max 5.000000 ... 4.000000
##
## StandardHours StockOptionLevel TotalWorkingYears \
## count 1470.0 1470.000000 1470.000000
## mean 80.0 0.793878 11.279592
## std 0.0 0.852077 7.780782
## min 80.0 0.000000 0.000000
## 25% 80.0 0.000000 6.000000
## 50% 80.0 1.000000 10.000000
## 75% 80.0 1.000000 15.000000
## max 80.0 3.000000 40.000000
##
## TrainingTimesLastYear WorkLifeBalance YearsAtCompany \
## count 1470.000000 1470.000000 1470.000000
## mean 2.799320 2.761224 7.008163
## std 1.289271 0.706476 6.126525
## min 0.000000 1.000000 0.000000
## 25% 2.000000 2.000000 3.000000
## 50% 3.000000 3.000000 5.000000
## 75% 3.000000 3.000000 9.000000
## max 6.000000 4.000000 40.000000
##
## YearsInCurrentRole YearsSinceLastPromotion YearsWithCurrManager
## count 1470.000000 1470.000000 1470.000000
## mean 4.229252 2.187755 4.123129
## std 3.623137 3.222430 3.568136
## min 0.000000 0.000000 0.000000
## 25% 2.000000 0.000000 2.000000
## 50% 3.000000 1.000000 3.000000
## 75% 7.000000 3.000000 7.000000
## max 18.000000 15.000000 17.000000
##
## [8 rows x 26 columns]
import os
cwd = os.getcwd()
print(cwd)
## DataMiningscience/RPYTHON_files
print("Path at terminal when executing this file")
## Path at terminal when executing this file
print(os.getcwd() + "\n")
## /DataMiningscience/RPYTHON_files
#matplotlib inline
#Import datavis libraries
import matplotlib.pyplot as plt
# Hide warnings if there are any
import warnings
warnings.filterwarnings('ignore')
import pandas_datareader.data as web
import numpy as np
import seaborn as sns; sns.set()
from datetime import datetime
from dateutil.parser import parse
import pandas as pd
#
start = datetime(2015, 1, 1)
end = datetime(2018, 3, 1)
#download Apple stock data
df = web.DataReader(['AAPL'], 'morningstar', start, end)
df=pd.DataFrame(df)
print(df.dtypes)
## select the Date and Symbol index and add as a main column
## Close float64
## High float64
## Low float64
## Open float64
## Volume int64
## dtype: object
df["Date"]=df.index.get_level_values('Date')
df["Symbol"]=df.index.get_level_values('Symbol')
df.tail(3)
#drop columns
df2=df.drop(columns=['Date','Symbol'])
#Convert index to column
df2=df2.reset_index()
#drop index
#df.drop(index='Date')
#We can use the drop parameter to avoid the old index being added as a column:
df3=df
df3.reset_index(drop=True)
print(df3.head(4))
## Close High Low Open Volume Date Symbol
## Symbol Date
## AAPL 2015-01-01 110.38 110.38 110.38 110.38 0 2015-01-01 AAPL
## 2015-01-02 109.33 111.44 107.35 111.39 53204626 2015-01-02 AAPL
## 2015-01-05 106.25 108.65 105.41 108.29 64285490 2015-01-05 AAPL
## 2015-01-06 106.26 107.43 104.63 106.54 65797116 2015-01-06 AAPL
df4 = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
df4.head()
#drop an index column
print(df4.reset_index(drop=True))
#df3.reset_index(level=['Date'])
#df3.MultiIndex.drop(labels, level=None, errors='raise')
## class max_speed
## 0 bird 389.0
## 1 bird 24.0
## 2 mammal 80.5
## 3 mammal NaN
df5=df2.drop(columns=['Symbol','Volume'])
#Set the index to become the
df5=df5.set_index(['Date'])
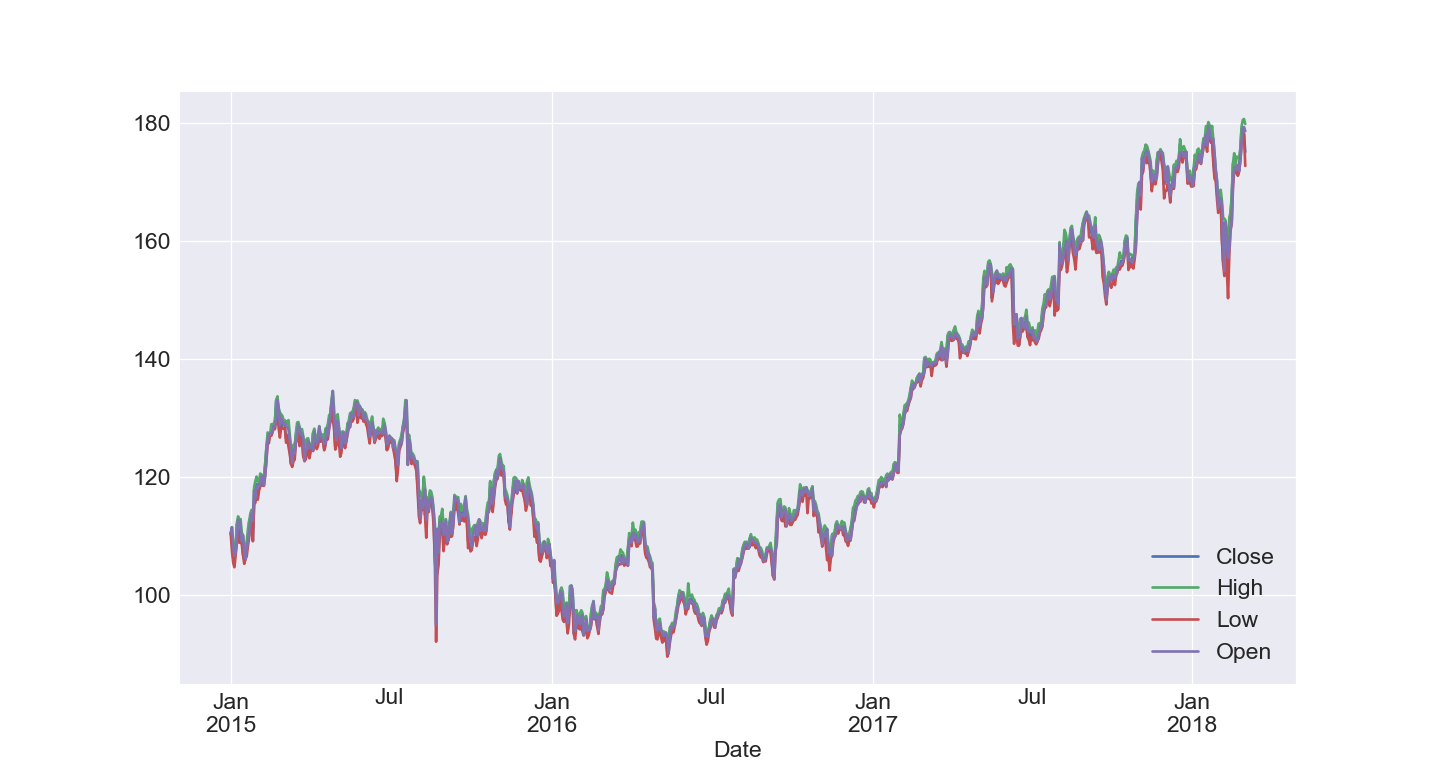
fig, ax = plt.subplots(1, 1,figsize=(20,10))
plt.subplots(1, 0)
params = {'legend.fontsize': 'x-large',
'figure.figsize': (15, 8),
'axes.labelsize': 'x-large',
'axes.titlesize':'x-large',
'xtick.labelsize':'x-large',
'ytick.labelsize':'x-large'}
plt.rcParams.update(params)
plt.title('Stock Prices ', fontsize=20)
plt.ylabel('Price', fontsize=20)
plt.xlabel('Date', fontsize=20)
df5.plot(lw=2,grid = True)
fig.savefig('Apple.jpg')
plt.grid(True)
plt.legend(loc='lower right')
plt.show()
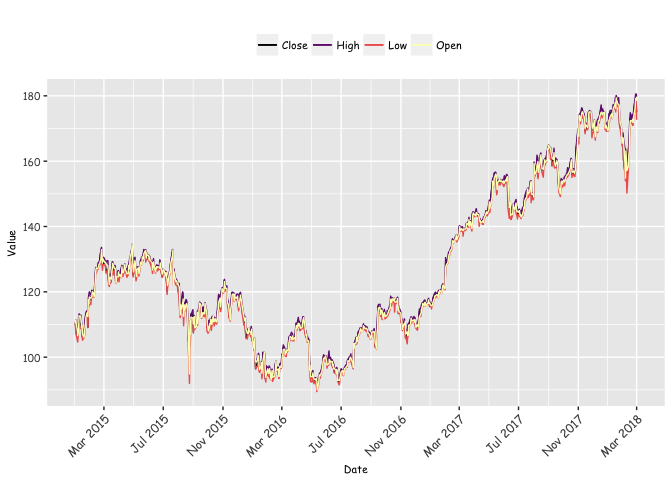
We can also plot transfer the data from the Python environment and plot with ggplot as follows:
#install.packages("viridis")
library(viridis)
df6=py$df3%>%mutate(Date=as.Date(Date))
ggplot(df6)+geom_line(aes(x=Date,y=Close,color="Close"))+geom_line(aes(x=Date,y=High,color="High"))+geom_line(aes(x=Date,y=Low,color="Low"))+geom_line(aes(x=Date,y=Open,color="Open"))+
scale_color_viridis(discrete=TRUE,option = "A")+
#scale_fill_viridis(discrete = T,option = "C")+
theme(
legend.position="top",
legend.direction="horizontal",
legend.title = element_blank(),
text=element_text(size=8, family="Comic Sans MS"),
axis.text.x=element_text(angle=45,hjust=1,size = 9),
axis.text.y=element_text(size = 8),
legend.text = element_text(size=8)
)+
labs(y="Value",x="Date",title="")+
# scale_x_date(date_labels = "%b %d")
#scale_x_date(labels = date_format("%m-%y"))
scale_x_date(breaks = date_breaks("4 month"),labels=date_format("%b %Y") )
df6%>% select(Date,High,Close,Low,Open,Symbol)%>%
gather(Name,Value,-Date,-Symbol)%>%mutate(Name=as.factor(Name))%>%
ggplot(aes(x=Date,y=Value,color=Name))+geom_line()+
scale_color_viridis(discrete=TRUE,option = "D")+
#scale_fill_viridis(discrete = T,option = "C")+
theme(
legend.title = element_blank(),
text=element_text(size=8, family="Comic Sans MS"),
axis.text.x=element_text(angle=45,hjust=1,size = 9),
axis.text.y=element_text(size = 8),
legend.text = element_text(size=8)
)+
scale_x_date(breaks = date_breaks("4 month"),labels=date_format("%b %Y") )
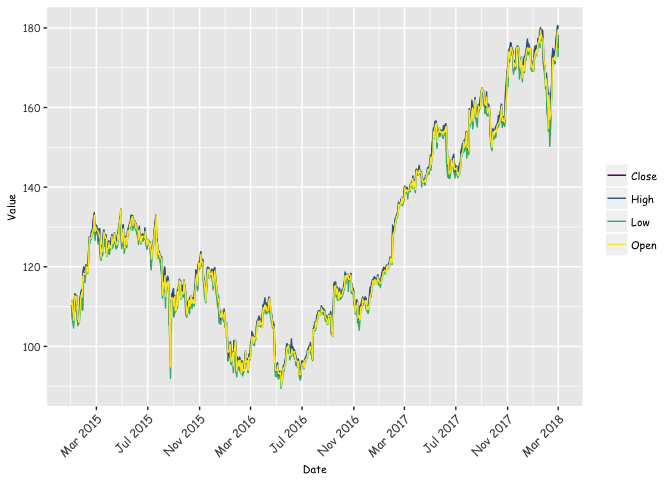
# scale_fill_manual(values=c("#B9DE28FF" , "#D1E11CFF" , "#E8E419FF"))
The reticulate Package
Another alternative to working with in R is via the reticulate package. The reticulate package has made it possible for several popular python libraries such as tensorflow and keras available in R. It provides a set of tools for interoperability between R and Python. It’s functionality include sourcing python scripts,using Python interactively within an R session and importing modules.
library(reticulate)
os <- import("os")
#get current working directory
os$getcwd()
## [1] "/DataMiningscience/RPYTHON_files"
#list files current directory
os$listdir(".")
## [1] ".DS_Store"
## [2] "2018-07-22-Working-with-Python-n-Rstudio.html"
## [3] "Apple.jpg"
## [4] "figure-html"
## [5] "RPYTHON.Rmd"
## [6] "RPYTHON_files"
## [7] "trig.jpg"
Python in R Markdown
from IPython import get_ipython
#get_ipython().magic('reset -sf')
import matplotlib.pyplot as plt
#%matplotlib inline
import numpy as np
fig, ax = plt.subplots(1, 1,figsize=(20,10))
plt.subplots(1, 0)
t=np.arange(-5,5,0.01)
s1=1+np.sin(0.5*np.pi*t)
s2=1+np.cos(0.5*np.pi*t)
plt.plot(t,s1, label="sine", linestyle='--')
plt.plot(t,s2, label="cosine", lw=2)
plt.grid(True)
plt.title('Sine and Cosine Functions ', fontsize=20)
plt.ylabel('y-axis', fontsize=20)
plt.xlabel('x-axis', fontsize=20)
plt.grid(True)
# Place a legend above this subplot, expanding itself to
# fully use the given bounding box.
#plt.legend(bbox_to_anchor=(0, 1.02, 1., .102), loc=3,
# ncol=1, mode="expand", borderaxespad=0.)
# Place a legend to the right of this smaller subplot.
plt.legend(bbox_to_anchor=(-0.1, 1.11), loc=2, borderaxespad=0.5)
#plt.legend(loc='lower right')
plt.savefig('trig.jpg')
plt.show()
#print(s)
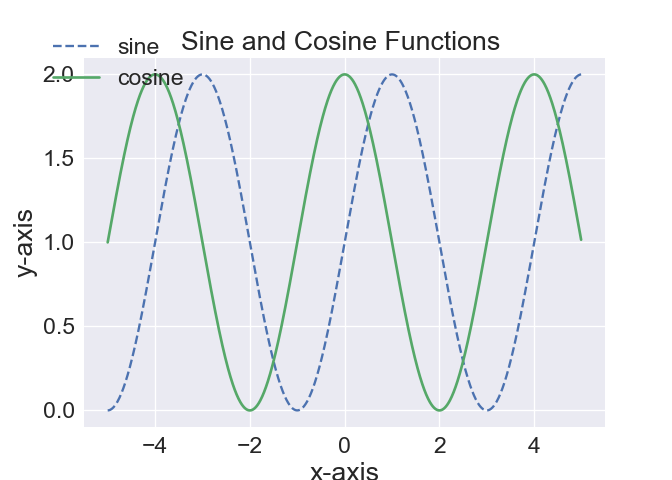
import pandas
employeedata = pandas.read_csv("https://raw.githubusercontent.com/NanaAkwasiAbayieBoateng/Datasets/master/EmployeeAttrition.csv")
employeedata = employeedata[employeedata['BusinessTravel'] == "Travel_Frequently"]
employeedata = employeedata[['Age', 'Attrition', 'BusinessTravel','DailyRate','Department']]
employeedata = employeedata.dropna()
library(ggplot2)
ggplot(py$employeedata, aes(Age,fill=Attrition)) + geom_histogram(bins = 30)
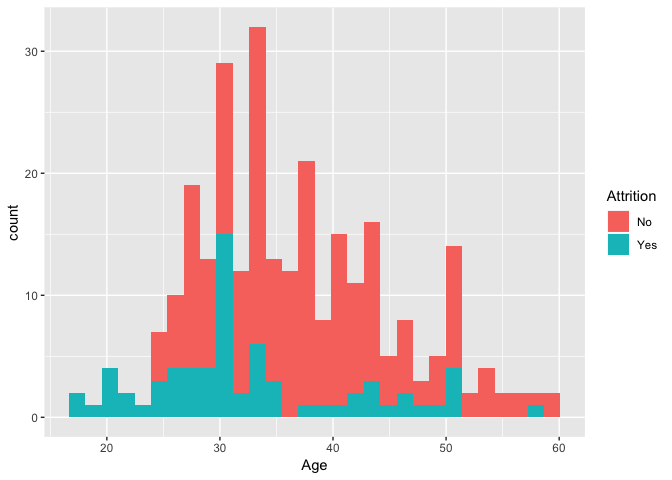
Sourcing Python scripts
A Python script can be sourced using source_python() function. For example, if you had the following Python script employeeAttrition.py:
source_python("/DataMiningscience/employeeAttrition.py")
employeedata <- read_employee("https://raw.githubusercontent.com/NanaAkwasiAbayieBoateng/Datasets/master/EmployeeAttrition.csv")
library(ggplot2)
ggplot(py$employeedata, aes(Age,fill=Attrition)) + geom_histogram(bins = 30)
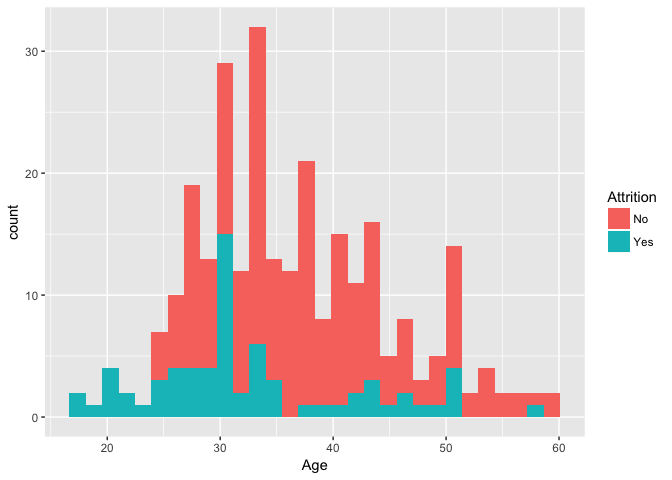
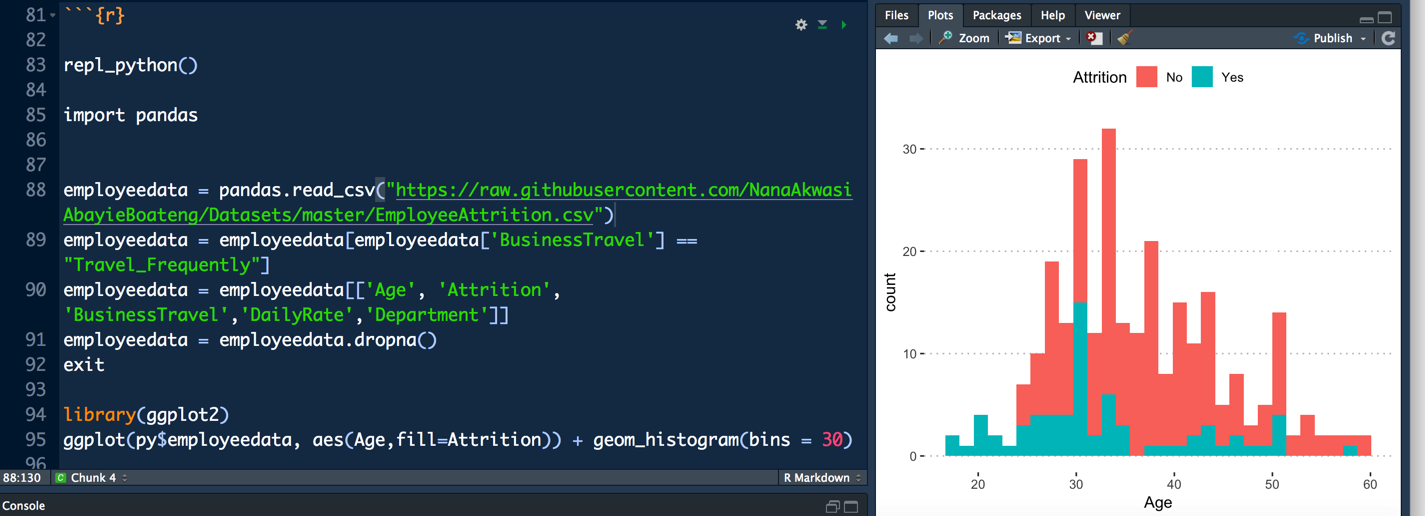
Python REPL
The repl_python() function allows switching between Python and R a breeze.First a call is made to repl_python() function , which provides a Python REPL embedded within your R session.Objects created within the Python REPL can be accessed from R using the py object exported from reticulate. The Python and R code can together be run in the R console like the example below.
# repl_python()
#
# import pandas
#
#
# employeedata = pandas.read_csv("https://raw.githubusercontent.com/NanaAkwasiAbayieBoateng/Datasets/master/EmployeeAttrition.csv")
# employeedata = employeedata[employeedata['BusinessTravel'] == "Travel_Frequently"]
# employeedata = employeedata[['Age', 'Attrition', 'BusinessTravel','DailyRate','Department']]
# employeedata = employeedata.dropna()
# exit
#
# library(ggplot2)
# ggplot(py$employeedata, aes(Age,fill=Attrition)) + geom_histogram(bins = 30)