Introduction
XLNet is a generalized autoregressive Transformer that enables learning bidirectional contexts by maximizing the expected likelihood of a sequence w.r.t. all possible permutations of the factorization order. XLNet employs Transformer-XL autoregressive model into pre-training but without the limitation of the fixed forward or backward factorization order of autoregressive models. XLNet achieves state-of-the-art results on various natural language task that involves long text sequence in question answering, sentiment analysis, natural language inference and document ranking. The permutation operation enables the context for each position to consist of tokens from both left and right. The bidirectional context in a sequence is captured by the expectation where each position learns to utilize contextual information from all positions.
The technical details is available in the paper XLNet: Generalized Autoregressive Pretraining for Language Understanding
import tensorflow as tf
# Get the GPU device name.
device_name = tf.test.gpu_device_name()
# The device name should look like the following:
if device_name == '/device:GPU:0':
print('Found GPU at: {}'.format(device_name))
else:
raise SystemError('GPU device not found')
Found GPU at: /device:GPU:0
In order for torch to use the GPU, we need to identify and specify the GPU as the device. Later, in our training loop, we will load data onto the device.
import torch
# If there's a GPU available...
if torch.cuda.is_available():
# Tell PyTorch to use the GPU.
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
# If not...
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
There are 1 GPU(s) available.
We will use the GPU: Tesla T4
Next, let’s install the transformers package from Hugging Face which will give us a pytorch interface for working with XLNet. This package strikes a nice balance between the high-level APIs (which are easy to use but don’t provide insight into how things work) and tensorflow code (which contains lots of unnecessary details).
#!pip install transformers=='2.8.0'
!pip install transformers
!pip install sentencepiece
Requirement already satisfied: transformers in /usr/local/lib/python3.7/dist-packages (2.9.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers) (3.0.12)
Requirement already satisfied: tokenizers==0.7.0 in /usr/local/lib/python3.7/dist-packages (from transformers) (0.7.0)
Requirement already satisfied: sacremoses in /usr/local/lib/python3.7/dist-packages (from transformers) (0.0.45)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from transformers) (2.23.0)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (2019.12.20)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from transformers) (1.19.5)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers) (4.41.1)
Requirement already satisfied: sentencepiece in /usr/local/lib/python3.7/dist-packages (from transformers) (0.1.95)
Requirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (7.1.2)
Requirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (1.0.1)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (1.15.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2020.12.5)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2.10)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (1.24.3)
Requirement already satisfied: sentencepiece in /usr/local/lib/python3.7/dist-packages (0.1.95)
!pip install transformers==2.9.0
!pip install pytorch_lightning==0.7.5
Collecting transformers==2.9.0
[?25l Downloading https://files.pythonhosted.org/packages/cd/38/c9527aa055241c66c4d785381eaf6f80a28c224cae97daa1f8b183b5fabb/transformers-2.9.0-py3-none-any.whl (635kB)
[K |████████████████████████████████| 645kB 14.1MB/s
[?25hCollecting tokenizers==0.7.0
[?25l Downloading https://files.pythonhosted.org/packages/ea/59/bb06dd5ca53547d523422d32735585493e0103c992a52a97ba3aa3be33bf/tokenizers-0.7.0-cp37-cp37m-manylinux1_x86_64.whl (5.6MB)
[K |████████████████████████████████| 5.6MB 30.1MB/s
[?25hRequirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (2019.12.20)
Requirement already satisfied: sentencepiece in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (0.1.95)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (2.23.0)
Requirement already satisfied: sacremoses in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (0.0.45)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (4.41.1)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (3.0.12)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from transformers==2.9.0) (1.19.5)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->transformers==2.9.0) (2020.12.5)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->transformers==2.9.0) (3.0.4)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->transformers==2.9.0) (1.24.3)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->transformers==2.9.0) (2.10)
Requirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers==2.9.0) (1.0.1)
Requirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers==2.9.0) (7.1.2)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers==2.9.0) (1.15.0)
Installing collected packages: tokenizers, transformers
Found existing installation: tokenizers 0.10.2
Uninstalling tokenizers-0.10.2:
Successfully uninstalled tokenizers-0.10.2
Found existing installation: transformers 4.5.1
Uninstalling transformers-4.5.1:
Successfully uninstalled transformers-4.5.1
Successfully installed tokenizers-0.7.0 transformers-2.9.0
Collecting pytorch_lightning==0.7.5
[?25l Downloading https://files.pythonhosted.org/packages/75/ac/ac03f1f3fa950d96ca52f07d33fdbf5add05f164c1ac4eae179231dfa93d/pytorch_lightning-0.7.5-py3-none-any.whl (233kB)
[K |████████████████████████████████| 235kB 19.5MB/s
[?25hCollecting future>=0.17.1
[?25l Downloading https://files.pythonhosted.org/packages/45/0b/38b06fd9b92dc2b68d58b75f900e97884c45bedd2ff83203d933cf5851c9/future-0.18.2.tar.gz (829kB)
[K |████████████████████████████████| 829kB 51.3MB/s
[?25hRequirement already satisfied: torch>=1.1 in /usr/local/lib/python3.7/dist-packages (from pytorch_lightning==0.7.5) (1.8.1+cu101)
Requirement already satisfied: numpy>=1.16.4 in /usr/local/lib/python3.7/dist-packages (from pytorch_lightning==0.7.5) (1.19.5)
Requirement already satisfied: tensorboard>=1.14 in /usr/local/lib/python3.7/dist-packages (from pytorch_lightning==0.7.5) (2.4.1)
Requirement already satisfied: tqdm>=4.41.0 in /usr/local/lib/python3.7/dist-packages (from pytorch_lightning==0.7.5) (4.41.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch>=1.1->pytorch_lightning==0.7.5) (3.7.4.3)
Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (56.0.0)
Requirement already satisfied: protobuf>=3.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (3.12.4)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (0.4.4)
Requirement already satisfied: grpcio>=1.24.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (1.32.0)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (1.8.0)
Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (1.15.0)
Requirement already satisfied: wheel>=0.26; python_version >= "3" in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (0.36.2)
Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (3.3.4)
Requirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (1.28.1)
Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (1.0.1)
Requirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (2.23.0)
Requirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.14->pytorch_lightning==0.7.5) (0.12.0)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.7/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=1.14->pytorch_lightning==0.7.5) (1.3.0)
Requirement already satisfied: importlib-metadata; python_version < "3.8" in /usr/local/lib/python3.7/dist-packages (from markdown>=2.6.8->tensorboard>=1.14->pytorch_lightning==0.7.5) (3.10.1)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard>=1.14->pytorch_lightning==0.7.5) (0.2.8)
Requirement already satisfied: rsa<5,>=3.1.4; python_version >= "3.6" in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard>=1.14->pytorch_lightning==0.7.5) (4.7.2)
Requirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard>=1.14->pytorch_lightning==0.7.5) (4.2.1)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.14->pytorch_lightning==0.7.5) (1.24.3)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.14->pytorch_lightning==0.7.5) (2020.12.5)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.14->pytorch_lightning==0.7.5) (2.10)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.14->pytorch_lightning==0.7.5) (3.0.4)
Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.7/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=1.14->pytorch_lightning==0.7.5) (3.1.0)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata; python_version < "3.8"->markdown>=2.6.8->tensorboard>=1.14->pytorch_lightning==0.7.5) (3.4.1)
Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.7/dist-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tensorboard>=1.14->pytorch_lightning==0.7.5) (0.4.8)
Building wheels for collected packages: future
Building wheel for future (setup.py) ... [?25l[?25hdone
Created wheel for future: filename=future-0.18.2-cp37-none-any.whl size=491058 sha256=a4af758272e984c76fa161aa7795d067c3d78c40178b10fd9a11d24986ead32d
Stored in directory: /root/.cache/pip/wheels/8b/99/a0/81daf51dcd359a9377b110a8a886b3895921802d2fc1b2397e
Successfully built future
Installing collected packages: future, pytorch-lightning
Found existing installation: future 0.16.0
Uninstalling future-0.16.0:
Successfully uninstalled future-0.16.0
Successfully installed future-0.18.2 pytorch-lightning-0.7.5
Load Data
The dataset for this exercise is from kaggle and located here.
import pandas as pd
import re
import os
import math
import torch
# import torch.nn as nn
from torch.nn import BCEWithLogitsLoss, NLLLoss
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
# from pytorch_transformers import XLNetModel, XLNetTokenizer, XLNetForSequenceClassification
from transformers import AdamW, XLNetTokenizer, XLNetModel, TFXLNetModel, XLNetLMHeadModel, XLNetConfig, XLNetForSequenceClassification
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import numpy as np
from tqdm import tqdm, trange
import matplotlib.pyplot as plt
import unicodedata
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix,roc_auc_score
import seaborn as sns
import itertools
import plotly
import seaborn as sns
from plotly import graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
from collections import Counter
%matplotlib inline
from zipfile import ZipFile
#!unzip /content/drive/MyDrive/Data/Fake_True_News.zip
zip_file = ZipFile('/content/drive/MyDrive/Data/Fake_True_News.zip')
zip_file
zip_file.infolist()
[<ZipInfo filename='Fake.csv' compress_type=deflate file_size=62789876 compress_size=23982401>,
<ZipInfo filename='True.csv' compress_type=deflate file_size=53582940 compress_size=18993224>]
import pandas as pd
from zipfile import ZipFile
True_data = pd.read_csv(zip_file.open('True.csv'),encoding='UTF-8')
True_data['label']= 1
True_data.head()
| title | text | subject | date | label | |
|---|---|---|---|---|---|
| 0 | As U.S. budget fight looms, Republicans flip t... | WASHINGTON (Reuters) - The head of a conservat... | politicsNews | December 31, 2017 | 1 |
| 1 | U.S. military to accept transgender recruits o... | WASHINGTON (Reuters) - Transgender people will... | politicsNews | December 29, 2017 | 1 |
| 2 | Senior U.S. Republican senator: 'Let Mr. Muell... | WASHINGTON (Reuters) - The special counsel inv... | politicsNews | December 31, 2017 | 1 |
| 3 | FBI Russia probe helped by Australian diplomat... | WASHINGTON (Reuters) - Trump campaign adviser ... | politicsNews | December 30, 2017 | 1 |
| 4 | Trump wants Postal Service to charge 'much mor... | SEATTLE/WASHINGTON (Reuters) - President Donal... | politicsNews | December 29, 2017 | 1 |
Fake_data = pd.read_csv(zip_file.open('Fake.csv'),encoding='UTF-8')
Fake_data['label']=0
Fake_data.head()
| title | text | subject | date | label | |
|---|---|---|---|---|---|
| 0 | Donald Trump Sends Out Embarrassing New Year’... | Donald Trump just couldn t wish all Americans ... | News | December 31, 2017 | 0 |
| 1 | Drunk Bragging Trump Staffer Started Russian ... | House Intelligence Committee Chairman Devin Nu... | News | December 31, 2017 | 0 |
| 2 | Sheriff David Clarke Becomes An Internet Joke... | On Friday, it was revealed that former Milwauk... | News | December 30, 2017 | 0 |
| 3 | Trump Is So Obsessed He Even Has Obama’s Name... | On Christmas day, Donald Trump announced that ... | News | December 29, 2017 | 0 |
| 4 | Pope Francis Just Called Out Donald Trump Dur... | Pope Francis used his annual Christmas Day mes... | News | December 25, 2017 | 0 |
data= pd.concat([True_data,Fake_data],axis=0)
from sklearn.utils import shuffle
data = shuffle(data)
print("number of rows of data {}".format(data.shape[0]))
data.head()
number of rows of data 44898
| title | text | subject | date | label | |
|---|---|---|---|---|---|
| 3409 | Trump administration moves to keep full CIA 't... | WASHINGTON (Reuters) - U.S. President Donald T... | politicsNews | June 2, 2017 | 1 |
| 19642 | AFTER 8 Years Of Silence From Obama On Cop Kil... | Here s just one of many discussions of assassi... | left-news | Nov 11, 2016 | 0 |
| 14906 | Russia, U.S. stalemate over Syria chemical wea... | UNITED NATIONS (Reuters) - Russia said on Mond... | worldnews | November 14, 2017 | 1 |
| 11211 | Trump fans in Iowa cheer his debate performance | WAUKEE, Iowa (Reuters) - It was not hard to te... | politicsNews | January 15, 2016 | 1 |
| 14858 | NEW YORK OFFICIALS Confirm Donald Trump’s Clai... | The media really wants to bury Trump on this b... | politics | Dec 2, 2015 | 0 |
temp = data['label'].value_counts()
#temp = pd.DataFrame(temp,columns=['label','counts'])
temp = pd.DataFrame(temp).reset_index()
temp.columns=['label','counts']
cm = sns.light_palette("green", as_cmap=True)
temp.style.background_gradient(cmap=cm)
#fig = px.scatter(temp, x="day", y="Counts",mode='lines+markers')
fig = go.Figure()
#fig.add_trace(go.bar(x=temp.day, y=temp.Counts ))
#fig = px.line(temp, x="day", y="Counts")
fig = px.bar(temp, x="label", y="counts",color="counts")
fig.update_layout(
title=" Frequency of Words Used In News per Month of the Year",
xaxis_title="Label",
yaxis_title="Frequency",
#legend_title="",
font=dict(
family="Courier New, monospace",
size=18,
color="white"
)
)
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="plotly_dark")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/file1.html")
We split the data into train and test, the training will later tbe split again into training and validation sets. The test set would be used for testing the model performance later on.
train ,test = train_test_split(data, random_state=2018, test_size=0.2)
print('Number of training sentences: {:,}\n'.format(train.shape[0]))
print('Number of testing sentences: {:,}\n'.format(test.shape[0]))
Number of training sentences: 35,918
Number of testing sentences: 8,980
Pre-processing Tweets
Preprocessing is done in general to clean up the text data before modeling. Some usual actions taken to clean up the text include removing unwanted characters, stripping of spaces and tekenizing the text data.
from nltk.tokenize import WordPunctTokenizer
import re
# import emoji
from bs4 import BeautifulSoup
import itertools
tok = WordPunctTokenizer()
pat1 = r'@[A-Za-z0-9]+'
pat2 = r'https?://[A-Za-z0-9./]+'
# Converts the unicode file to ascii
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence_english(w):
w = unicode_to_ascii(w.lower().strip())
# creating a space between a word and the punctuation following it
# eg: "he is a boy." => "he is a boy ."
# Reference:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# replacing everything with space except (a-z, A-Z, ".", "?", "!", ",")
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
#w = re.sub(r'[^Ɔ-ɔɛƐ]+', r' ', w)
#strip() Parameters
#chars (optional) - a string specifying the set of characters to be removed.
#If the chars argument is not provided, all leading and trailing whitespaces are removed from the string.
w = w.rstrip().strip()
# Fix misspelled words
w = ''.join(''.join(s)[:2] for _, s in itertools.groupby(w))# checking that each character should occur not more than 2 times in every word
# Tokenizing ,change cases & join together to remove unneccessary white spaces
w = tok.tokenize(w)
w = (" ".join(w)).strip()
return w
Checking the distribution of token lengths
The distribution of the token lengths
from transformers import XLNetTokenizer, XLNetLMHeadModel
import torch
tokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')
model = XLNetLMHeadModel.from_pretrained('xlnet-large-cased')
# We show how to setup inputs to predict a next token using a bi-directional context.
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is very <mask>", add_special_tokens=False)).unsqueeze(0) # We will predict the masked token
perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)
perm_mask[:, :, -1] = 1.0 # Previous tokens don't see last token
target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float) # Shape [1, 1, seq_length] => let's predict one token
target_mapping[0, 0, -1] = 1.0 # Our first (and only) prediction will be the last token of the sequence (the masked token)
from transformers import XLNetTokenizer, XLNetModel
PRE_TRAINED_MODEL_NAME = 'xlnet-base-cased'
tokenizer = XLNetTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME, do_lower_case=True)
token_lens = []
for txt in data['text']:
tokens = tokenizer.encode(txt, max_length=512)
token_lens.append(len(tokens))
data["token_length"] = token_lens
import plotly.figure_factory as ff
import numpy as np
# Group data together
hist_data = [data[data.label==0]["token_length"], data[data.label==1]["token_length"]]
group_labels = ['Fake', 'Real']
colors = ['slategray', 'magenta']
# Create distplot with custom bin_size
fig = ff.create_distplot(hist_data, group_labels, bin_size=.2,
curve_type='normal', # override default 'kde'
colors=colors)
#fig = ff.create_distplot(hist_data, group_labels, show_hist=False, colors=colors)
# Add title
#fig.update_layout(title_text='Distribution of Text Token Counts')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout(xaxis_range=[0,600])
fig.update_layout(yaxis_range=[0,0.04])
fig.update_layout( template="plotly")
fig.update_layout(
autosize=False,
width=1000,
height=600,)
fig.update_layout(
title=" Distribution of Text Token Length",
xaxis_title="Token Length",
yaxis_title="Frequency")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/file2.html")
# cleaning tweets
train['text_cleaned'] = list(map(lambda x: preprocess_sentence_english(x),train['text']) )
test['text_cleaned'] = list(map(lambda x: preprocess_sentence_english(x),test['text']) )
train.head()
| title | text | subject | date | label | text_cleaned | |
|---|---|---|---|---|---|---|
| 14999 | CNBC DEBATE HACK Proves Allegiance To Democrat... | By looking at the two Democrat presidential ca... | politics | Oct 31, 2015 | 0 | by looking at the two democrat presidential ca... |
| 18345 | Putin: Russia-U.S. ties may improve through jo... | MOSCOW (Reuters) - President Vladimir Putin sa... | worldnews | October 4, 2017 | 1 | moscow reuters president vladimir putin said o... |
| 17512 | EU plans Brexit summit gesture, May hints on cash | BRUSSELS (Reuters) - Britain will be offered a... | worldnews | October 13, 2017 | 1 | brussels reuters britain will be offered a goo... |
| 394 | Lower taxes, big gains: The stocks poised to w... | NEW YORK (Reuters) - A proposal driven by Pres... | politicsNews | December 1, 2017 | 1 | new york reuters a proposal driven by presiden... |
| 9004 | Here Are The Right-Wing Scumbags The Bundy Mi... | When the tense standoff between federal agents... | News | January 3, 2016 | 0 | when the tense standoff between federal agents... |
The sentences and labels can be conveted yo a nummp array by using the values function.
extract the sentences and labels of our training set as numpy ndarrays.
sentences = train.text_cleaned.values
labels = train.label.values
sentences[0:5]
array(['by looking at the two democrat presidential candidates left standing , most americans would think their platform is primarily about the destruction of capitalism and gun control . the real truth however , is that the democrat party knows without their unyielding support for the culture of death , they would cease to exist . the sickening truth is , they either support the killing of the most vulnerable or it s curtains for them . what does that say about how far our society has fallen when leftist tv hosts celebrate china s brutal one child policy on twitter ? quintanilla may not have been endorsing the one child policy , but he didn t offer any overt or even implied criticism of it either . in fact , saying it worked sounds a lot like he is suggesting it was a success . the problem , of course , is that the one child policy , which china converted to a two child policy this week , was a brutal , harrowing invasion of the human rights of millions of families under the guise of national policy . since , an estimated million women a year underwent abortions , many of them forced to do so by government officials . another million women were sterilized under the same policy . https twitter . com carlquintanilla status these practices mostly went unseen and unnoticed in the era before social media and digital cameras . in , the world got to see the result of this policy on one young woman when her family members posted an image of her lying next to her dead baby after she d been forced to have an abortion . the young woman , feng jianmei , already had one child so after she became pregnant again , family planning officials called her house to persuade her to have an abortion . when that failed , they showed up at her home and spent hours pressuring her for consent . jianmei slipped out of the house but was followed by a group of officials to her aunt s house . after briefly escaping and hiding under the bed of a relative , jianmei was found by the government officials and was reportedly carried out by four men . here is the horrible story about forced abortions in china and their victims meanwhile , family planning officials were negotiating with jianmei s husband . at first they demanded , , but then dropped the birth planning fee to around , . in any case , it was more than he could raise . finally , jianmei was forced to give consent by having her thumbprint placed on a form and was injected with a drug that killed her baby . her family posted this image , which went viral , of jianmei with her dead daughter . for criticizing the government , government officials led a march denouncing her family as traitors , and her husband was beaten . and that nightmare is not the only kind of suffering caused by the policy . those who dared to violate the policy had to keep their secret children out of sight of government officials . as the washington post reported last month , the consequences of getting caught were severe it was terrifying if you had an over quota child , my father says now . if the government knew , you would be in trouble . people would come to your house , remove all your grains and do anything they could to you . and sometimes , they d destroy your house . my mother recalls even for a new house , they d get on the roof , rip it apart and bulldoze the entire house . we had to keep moving and hiding . it was really painful for us . we knew it wasn t a long term solution . the one child policy was a decades long campaign of forced abortion , extortion , sterilization , and terror that traumatized hundreds of millions of people . saying it worked seems like an odd way to sum up such a policy . via breitbart news',
'moscow reuters president vladimir putin said on wednesday that ties with u . s . president donald trump s administration were not without problems , but he hoped that mutual interests of russia and the united states in fighting terrorism would help improve moscow s relations with washington . some forces are making use of russian american relations to resolve internal political problems in the united states , putin told an energy forum in moscow . i believe that such a person like trump , with his character , will never be hostage to someone s interests . moscow has lots of friends in the united states who genuinely want to improve relations with russia , putin added .',
'brussels reuters britain will be offered a goodwill gesture at a european union summit next week , european nations agreed on friday , seeking to break the deadlock over brexit , but no watering down of their demand for tens of billions of euros they say britain owes . british prime minister theresa may also indicated she might make a move at next week s summit . a spokeswoman said there will be more to say there on a promise may made last month to honor financial commitments when britain leaves . both sides are making the moves to end an apparent stalemate in talks on britain s leaving the eu . at heart is a proposal by summit chair donald tusk to tell may next week that the eu will start internal work on a post brexit transition plan . this is a very big gesture towards britain , maybe way too big , a senior eu diplomat said ahead of an evening meeting of envoys from the remaining states to discuss tusk s draft for a statement to made after leaders meet in a week s time . ambassadors broadly agreed the plan on friday despite scepticism , including from powerhouse germany . they requested some harder language to ram home that any offer is conditional on britain making progress toward agreeing brussels terms . time is running out , german chancellor angela merkel s spokesman had warned after week of stalemate in negotiations and faction fighting within may s government that have raised concerns that talks could collapse , leaving britain bumping out into legal limbo in march . hammering the point , eu chief executive jean claude juncker said in luxembourg they have to pay . they have to pay . underscoring tensions , british finance minister philip hammond referred to the eu as the enemy at one point , but then apologized . his remark came as he defended himself against accusations from hardline brexit supporters who say he is soft on brussels . businesses planning investment decisions are calling for a clear idea by the new year of how the split and subsequent years of transition to a new trade relationship will function . otherwise , some firms say , they may assume a disruptive hard brexit and move some operations to continental europe . as the process approaches the half way stage between last june s referendum vote for brexit and britain s departure on march , , tensions are building not just between the two negotiating sides but also within the bloc of . while hardliners would prefer less or no talk of a future after brexit and more about demanding money , others are keen to give may , beleaguered at home , something to show for the effort to compromise she displayed in a speech at florence last month . one diplomat called the draft a search and rescue mission to help the british premier out of a jam . another said it was a bid to break stalemate and avert disaster over the winter some states were not very happy about this but what else can we do ? the diplomat added . we are trying to reach out . but then the diplomat added they must come up with something on the money . diplomats said germany and france coordinated on friday , to limit any watering down of the eu position that its negotiator , michel barnier , cannot so much as mention to his british counterparts what might come after brexit until leaders deem there has been sufficient progress on three issues the eu says must be settled before britain leaves . these are the rights of eu citizens in britain , northern ireland s new eu border and the intractable brexit bill . tusk , who met merkel and french president emmanuel macron in a week when he has spoken to almost all other eu leaders including may , offered a draft text saying there is not enough progress but welcoming the advances there have been and flagging a hope that the next summit in december could open trade talks . in its strongest conclusion , it proposes that barnier start working out internally without negotiating with london what will happen after brexit . barnier himself has sought flexibility to break the deadlock , diplomats say . if this is the concession may needs to be able to make a move on financial settlement , let s try it , said a diplomat from one of britain s close eu trading partners . she is so weak at the moment she can do nothing . and we need the money . despite protestations of unity , some diplomats detect nuance in approaches to the prospect of talks collapsing , with those countries with most to lose from trade barriers with britain most keen to avert a meltdown . essentially that means its near neighbors like the nordic states , the netherlands and ireland .',
'new york reuters a proposal driven by president donald trump to overhaul the country s tax system is moving through u . s . congress , lifting the overall stock market and raising hopes that corporate earnings will get a boost . the s p . spx rallied this week as the drive to push sweeping tax legislation through the u . s . senate gained momentum , although gains were tempered by a report that former national security adviser michael flynn was prepared to testify that before taking office trump had directed him to make contact with russians . senate republicans said on friday they had gathered the votes needed to pass a sweeping tax overhaul . while negotiations are ongoing , the legislation could cut the corporate tax rate to as low as percent from percent . ubs strategists project that overall s p earnings would rise by . percent should the corporate tax rate fall to percent and increase by . percent should the rate go to percent . but certain stocks could benefit more than others from the republican led plans . it will be favorable to companies with primarily domestic business that are paying close to the full tax rate , said john carey , portfolio manager at amundi pioneer asset management in boston . investors appear to have already rotated into some of these tax sensitive areas . some market watchers caution about generalizing winners , noting big differences in effective rates between companies in the same sectors . but strategists point to industries with a concentration of companies poised to benefit , particularly from a lower corporate tax rate . for a graphic on industries that stand to win from corporate tax cuts , click reut . rs zvjls for a graphic on sector benefits from a corporate tax cut , click reut . rs amn au high tax stocks underperform in reut . rs amdrp of the major s p sectors , financials pay the highest effective tax rate at . percent , according to a wells fargo analysis of historical tax rates . brian klock , managing director in equity research at keefe , bruyette woods who covers large regional banks , expects tax cuts to add percent to median bank earnings in and percent in . we re assuming whatever the benefit is will drop right to the bottom line , klock said . they won t give up on loan pricing or put any big investments in . with the increased capital they ll return it to shareholders . among large regional banks , zions bancorp zion . o , m t bank corp mtb . n and comerica inc cma . n stand to benefit the most , klock said . transportation ranks among the top industries expected to receive a big earnings boost from a lower corporate tax rate , according to ubs . u . s . railroads such as union pacific corp unp . n and csx corp csx . o are almost entirely exposed to the u . s . statutory rates , said morningstar analyst keith schoonmaker . railroads would benefit from provisions allowing them to expense their capital expenditures in one year as opposed to over time , lowering their taxable income , schoonmaker said . we ll see what comes out as far as the ability to depreciate immediately , but that certainly would be beneficial because they are all big capital spenders , schoonmaker said , noting that railroads spend percent to percent of revenue on capital expenditures . airlines stand to gain from lower tax rates , analysts said , with ubs pointing to alaska air group inc alk . n and southwest airlines co luv . n as possible winners . domestically geared healthcare companies that focus on services would likely benefit more from tax rate reductions than pharmaceutical and medical device companies that sell their products overseas . healthcare services is one of the most taxed industries and would be a big beneficiary of reductions in corporate tax rates , lance wilkes , an analyst at bernstein , said in a recent note . the s p healthcare providers and services index . splrchcps , which includes health insurers such as anthem inc antm . n , drug wholesalers like amerisourcebergen corp abc . n , and hospital operators such as hca healthcare inc hca . n , has gained . percent this week . according to leerink analyst ana gupte , a corporate tax rate cut to percent could boost health insurer earnings by about percent to percent , but some of those gains would be expected to be passed through to employer and individual customers . other potential big winners include home health services company almost family inc afam . o , lab testing company quest diagnostics inc dgx . n and pharmacy benefit manger express scripts holding esrx . o , according to jefferies analyst brian tanquilut . department stores head the list of retailers that will benefit because they have among the heaviest u . s . exposure , said bridget weishaar , senior equity analyst at morningstar . weishaar points to macy s inc m . n , nordstrom inc jwn . n and kohls corp kss . n as potential winners among department stores , as well as victoria s secret owner l brands lb . n and apparel retailer ross stores rost . o . retail companies will benefit from paying a lower tax rate , weishaar said . consumers hopefully will have additional cash , which will help consumer discretionary spending . telecom companies , including at t inc t . n and verizon communications inc vz . n , also stand to gain . they re domestically focused companies with a very high percentage of their employee base in the u . s . and significant amounts of investments in u . s . infrastructure , said amir rozwadowski , telecom equity analyst at barclays . therefore they re predisposed to benefit from tax reform . at t has climbed . percent this week , while verizon has surged percent .',
'when the tense standoff between federal agents and a group of right wing extremists at cliven bundy s ranch ended in a stalemate , it was only a matter of time before we heard from the emboldened patriots again . on january , they showed up unannounced and unwelcome in oregon . towing with them a large arsenal of weapons and vowing to die in a shoot out if police or federal agents removed them , cliven s sons ammon and ryan bundy seized a federal wildlife building and said they were prepared to stay there indefinitely until their demands the unconditional surrender of the united states government and the ceding of federal land to ranchers like the bundy family are met . it s clear that ammon bundy , the ringleader , wants to build an army . in a statement , he begged fellow anti government patriots to stand up and come to harney county . we need your help and we are asking for it . and the bundy family made no secret of the violence underlining the protest . i talked to ryan bundy on the phone again . he said they re willing to kill and be killed if necessary . oregonunderattack ian kullgren iankullgren january , while ammon has framed the issue as one of freedom vs . tyranny , the real reason they showed up was to protect two oregon ranchers , father and son dwight and steven hammond . like cliven bundy , the hammonds had gotten used to abusing public lands to feed their livestock on and felt that it was now their right to do so . who are the hammonds ? based on their actions a pair of scumbags who were willing to destroy a large area of federally protected land just to protect themselves from being exposed as criminals . in , they purposely set a series of wildfires on government land in order to hide their poaching activities . the fires turned into a raging inferno that nearly killed a few local residents , destroyed acres of public land and killed countless animals that were meant to be safe . the jury convicted both of the hammonds of using fire to destroy federal property for a arson known as the hardie hammond fire , located in the steens mountain cooperative management and protection area . witnesses at trial , including a relative of the hammonds , testified the arson occurred shortly after steven hammond and his hunting party illegally slaughtered several deer on blm property . jurors were told that steven hammond handed out strike anywhere matches with instructions that they be lit and dropped on the ground because they were going to light up the whole country on fire . these are the people bundy s armed militia group came to oregon to defend . they would set a deadly wildfire to protect themselves and ruin the land for anyone else because freedom . if the definition of terrorism is the use of violence and intimidation to achieve a political goal , then let s call this what it is terrorism . ironically , the hammonds themselves want nothing to do with the standoff . their lawyer disavowed the group from the start . the hammonds are already facing jail sentences for their crimes . they ve correctly guessed that adding stoking an armed insurrection would only keep them in jail longer . from interviews ammon bundy has given while in oregon , it s clear that he has an idea of himself as a right wing martyr . as such , he and his fellow group of anti government terrorists are clearly willing to die for their cause . they ve brought with them enough guns to see that they take down as many innocent people as they can before that happens . so far , federal agencies and the harney county sheriff s department are taking a light approach the the occupation . not keen to start another waco , the authorities are trying to reason with the group rather than go in shooting . it remains to be seen whether a group that invaded a small wildlife reserve building while wearing camo fatigues and carrying rifles can be reasoned with . feature image via cbc screengrab'],
dtype=object)
3. Tokenization & Input Formatting
Before we can feed our data to XLNet, we have to transform it to a format that works with XLNet.
3.1 XLNet Tokenizer
To feed our text to XLNet, it must be split into tokens, and then these tokens must be mapped to their index in the tokenizer vocabulary.
The XLNetTokenizer and the pretrained cased version of the XLNetModel from huggingface can be loaded here. The tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. This model is also a PyTorch torch.nn.Module subclass and can be used as a regular pytroch module. The Tensorflow equivalent is the TFXLNetModel.
from transformers import XLNetTokenizer, XLNetModel
PRE_TRAINED_MODEL_NAME = 'xlnet-base-cased'
tokenizer = XLNetTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME, do_lower_case=True)
Here, let’s apply the tokenizer on a single sentence and output it together wit it’s token id’s to demonstrate how the tokenizer work.
print(' Original sentence {}: '.format( sentences[1]))
print('Tokenized sentence {}: '.format(tokenizer.tokenize(sentences[1])))
# Print the tweet mapped to token ids.
print('Token IDs {}: '.format(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[1]))))
Original sentence moscow reuters president vladimir putin said on wednesday that ties with u . s . president donald trump s administration were not without problems , but he hoped that mutual interests of russia and the united states in fighting terrorism would help improve moscow s relations with washington . some forces are making use of russian american relations to resolve internal political problems in the united states , putin told an energy forum in moscow . i believe that such a person like trump , with his character , will never be hostage to someone s interests . moscow has lots of friends in the united states who genuinely want to improve relations with russia , putin added .:
Tokenized sentence ['▁mo', 'sco', 'w', '▁', 're', 'uter', 's', '▁president', '▁v', 'la', 'di', 'mir', '▁put', 'in', '▁said', '▁on', '▁we', 'd', 'nes', 'day', '▁that', '▁ties', '▁with', '▁', 'u', '▁', '.', '▁', 's', '▁', '.', '▁president', '▁don', 'ald', '▁trump', '▁', 's', '▁administration', '▁were', '▁not', '▁without', '▁problems', '▁', ',', '▁but', '▁he', '▁hoped', '▁that', '▁mutual', '▁interests', '▁of', '▁', 'rus', 'sia', '▁and', '▁the', '▁united', '▁states', '▁in', '▁fighting', '▁terrorism', '▁would', '▁help', '▁improve', '▁mo', 'sco', 'w', '▁', 's', '▁relations', '▁with', '▁washing', 'ton', '▁', '.', '▁some', '▁forces', '▁are', '▁making', '▁use', '▁of', '▁', 'russian', '▁', 'american', '▁relations', '▁to', '▁resolve', '▁internal', '▁political', '▁problems', '▁in', '▁the', '▁united', '▁states', '▁', ',', '▁put', 'in', '▁told', '▁an', '▁energy', '▁forum', '▁in', '▁mo', 'sco', 'w', '▁', '.', '▁', 'i', '▁believe', '▁that', '▁such', '▁a', '▁person', '▁like', '▁trump', '▁', ',', '▁with', '▁his', '▁character', '▁', ',', '▁will', '▁never', '▁be', '▁hostage', '▁to', '▁someone', '▁', 's', '▁interests', '▁', '.', '▁mo', 'sco', 'w', '▁has', '▁lots', '▁of', '▁friends', '▁in', '▁the', '▁united', '▁states', '▁who', '▁genuinely', '▁want', '▁to', '▁improve', '▁relations', '▁with', '▁', 'rus', 'sia', '▁', ',', '▁put', 'in', '▁added', '▁', '.']:
Token IDs [6353, 5993, 694, 17, 88, 12105, 23, 379, 2721, 867, 1528, 6687, 331, 153, 42, 31, 80, 66, 4048, 765, 29, 3278, 33, 17, 660, 17, 9, 17, 23, 17, 9, 379, 220, 11945, 24716, 17, 23, 1048, 55, 50, 286, 708, 17, 19, 57, 43, 3577, 29, 5321, 2451, 20, 17, 7488, 7192, 21, 18, 9114, 1035, 25, 1501, 3140, 74, 222, 1474, 6353, 5993, 694, 17, 23, 1704, 33, 11048, 577, 17, 9, 106, 742, 41, 441, 164, 20, 17, 23975, 17, 15916, 1704, 22, 4885, 2854, 413, 708, 25, 18, 9114, 1035, 17, 19, 331, 153, 258, 48, 861, 4282, 25, 6353, 5993, 694, 17, 9, 17, 150, 676, 29, 148, 24, 601, 115, 24716, 17, 19, 33, 45, 1542, 17, 19, 53, 287, 39, 8840, 22, 886, 17, 23, 2451, 17, 9, 6353, 5993, 694, 51, 3895, 20, 1003, 25, 18, 9114, 1035, 61, 17874, 210, 22, 1474, 1704, 33, 17, 7488, 7192, 17, 19, 331, 153, 462, 17, 9]:
3.2 Tokenize Dataset
XLNet model has several inputs which is fed to. Among them are the following:
-
inputs_ids : Indices of input sequence tokens in the vocabulary. It is obtained by using
transformers.XLNetTokenizerfunction. These are the integer id’s/index of the input tokens generated by the tokenizer. -
token_type_ids : Segment token indices to indicate first and second portions of the inputs. Indices are selected in
[0, 1]: -
0 corresponds to a sentence A token,
-
1 corresponds to a sentence B token.
-
attention_mask : Mask to avoid performing attention on padding token indices. Mask values selected in
[0, 1]. - 1 for tokens that are not masked
-
0 for tokens that are masked.
- labels: a single value of 1 or 0. For our data real news is 1 and fake news is 0.
There are many more other optional inputs. For additional input functions look up here.
To format inputs arrays to be the same length as required by XLNet, we can specify a maximum sequence length then pad sequences with length less this maximum with zeros.Sequences with lengths greater than the maximum is truncated. The paading short sequences and truncating longer sequences at the maximum length specified formats all the input arrays to the same size.
#def tokenize_inputs(text_list, tokenizer, num_embeddings=120):
def tokenize_inputs(text_list, tokenizer, num_embeddings=120):
"""
Tokenizes the input text input into ids. Appends the appropriate special
characters to the end of the text to denote end of sentence. Truncate or pad
the appropriate sequence length.
"""
# tokenize the text, then truncate sequence to the desired length minus 2 for
# the 2 special characters
tokenized_texts = list(map(lambda t: tokenizer.tokenize(t)[:num_embeddings-2], text_list))
# convert tokenized text into numeric ids for the appropriate LM
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
# append special token "<s>" and </s> to end of sentence
input_ids = [tokenizer.build_inputs_with_special_tokens(x) for x in input_ids]
# pad sequences
input_ids = pad_sequences(input_ids, maxlen=num_embeddings, dtype="long", truncating="post", padding="post")
return input_ids
def create_attn_masks(input_ids):
"""
Create attention masks to tell model whether attention should be applied to
the input id tokens. Do not want to perform attention on padding tokens.
"""
# Create attention masks
attention_masks = []
# Create a mask of 1s for each token followed by 0s for padding
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
return attention_masks
# Tokenize all of the sentences and map the tokens to thier word IDs.
input_ids = tokenize_inputs(sentences, tokenizer, num_embeddings=120)
attention_masks = create_attn_masks(input_ids)
# Convert the lists into tensors.
# input_ids = torch.cat(input_ids, dim=0)
# attention_masks = torch.cat(attention_masks, dim=0)
input_ids = torch.from_numpy(input_ids)
attention_masks = torch.tensor(attention_masks)
labels = torch.tensor(labels)
# Print sentence 0, now as a list of IDs.
print('Original: ', sentences[1])
print('Token IDs:', input_ids[1])
print('Token IDs:', attention_masks[1])
Original: moscow reuters president vladimir putin said on wednesday that ties with u . s . president donald trump s administration were not without problems , but he hoped that mutual interests of russia and the united states in fighting terrorism would help improve moscow s relations with washington . some forces are making use of russian american relations to resolve internal political problems in the united states , putin told an energy forum in moscow . i believe that such a person like trump , with his character , will never be hostage to someone s interests . moscow has lots of friends in the united states who genuinely want to improve relations with russia , putin added .
Token IDs: tensor([ 6353, 5993, 694, 17, 88, 12105, 23, 379, 2721, 867,
1528, 6687, 331, 153, 42, 31, 80, 66, 4048, 765,
29, 3278, 33, 17, 660, 17, 9, 17, 23, 17,
9, 379, 220, 11945, 24716, 17, 23, 1048, 55, 50,
286, 708, 17, 19, 57, 43, 3577, 29, 5321, 2451,
20, 17, 7488, 7192, 21, 18, 9114, 1035, 25, 1501,
3140, 74, 222, 1474, 6353, 5993, 694, 17, 23, 1704,
33, 11048, 577, 17, 9, 106, 742, 41, 441, 164,
20, 17, 23975, 17, 15916, 1704, 22, 4885, 2854, 413,
708, 25, 18, 9114, 1035, 17, 19, 331, 153, 258,
48, 861, 4282, 25, 6353, 5993, 694, 17, 9, 17,
150, 676, 29, 148, 24, 601, 115, 24716, 4, 3])
Token IDs: tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:11: UserWarning:
To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
3.4. Training & Validation Split¶
Divide up our training set to use 80% for training and 20% for validation.
from torch.utils.data import TensorDataset, random_split
# Combine the training inputs into a TensorDataset.
dataset = TensorDataset(input_ids, attention_masks, labels)
# Create a 80-20 train-validation split.
# Calculate the number of samples to include in each set.
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
# Divide the dataset by randomly selecting samples.
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
# Checking whether the distribution of target is consitent across both the sets
label_temp_list = []
for a,b,c in train_dataset:
label_temp_list.append(c)
print('{:>5,} training samples'.format(train_size))
print('{:>5,} training samples with real news'.format(sum(label_temp_list)))
label_temp_list = []
for a,b,c in val_dataset:
label_temp_list.append(c)
print('{:>5,} validation samples'.format(val_size))
print('{:>5,} validation samples with real news'.format(sum(label_temp_list)))
28,734 training samples
13,655 training samples with real news
7,184 validation samples
3,450 validation samples with real news
The PyTorch torch.utils.data.DataLoader class Combines a dataset and a sampler, and provides an iterable over the given dataset.
The DataLoader supports both map-style and iterable-style datasets with single- or multi-process loading, customizing loading order and optional automatic batching (collation) and memory pinning. The iterator saves memory during training since the entire dataset does not have to be loaded into memory.
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# The DataLoader needs to know our batch size for training, so we specify it
# here. Batch size of 16 or 32.
batch_size = 16
# Create the DataLoaders for our training and validation sets.
# We'll take training samples in random order.
train_dataloader = DataLoader(
train_dataset, # The training samples.
sampler = RandomSampler(train_dataset), # Select batches randomly
batch_size = batch_size # Trains with this batch size.
)
# For validation the order doesn't matter, so we'll just read them sequentially.
validation_dataloader = DataLoader(
val_dataset, # The validation samples.
sampler = SequentialSampler(val_dataset), # Pull out batches sequentially.
batch_size = batch_size # Evaluate with this batch size.
)
4. Fine - Tuning our Classification Model
There are several pretrained XLNet models from hugginface namely xlnet-base-cased, xlnet-large-caseed etc. We would be use xlnet-base-cased which is a 12-layer, 768-hidden, 12-headsTransformel XL model with both lower and upper case in the training data used in creating the pretrained model. For comprehensive list of the various pretrained XLNet models from huggingface, check out this link here.
Transfer learning is the process of using a pretrained model, keeping most of the layers of the model and modifiying the last layer to adapt to the data of interest. It allows us to migrate the knowledge learned from the source dataset to a target dataset. Transfer learning allows us to scale over issues such as low accuracy that results from training a model on relatively small dataset and also computational resource constraints in training large models. It allows us to take advantage of the patterns already learned in a prevoius layers of a large model and adapt it to our dataset. Further information on fine - tuning is available in textbook Dive into Deep Learning which discusses Fine - Tuning in chapter 13 section 2 here. In fine- tuning we assume the output layer of the source model is similar to our target label for example we use a pre-trained sequence classification model to fine- tune our dataset which is of sequence classification nature and not some other task such as question answering. The output layer has size equal to the number of classes in our target label. We train the target model on our target dataset. The output layer is trained from scratch while the parameters of all remaining layers are fine-tuned based on the parameters of the source model. The target model replicates all model designs and their parameters on the source model, except the output layer, and fine-tunes these parameters based on the target dataset. In contrast, the output layer of the target model needs to be trained from scratch if not using transfer learning.
class XLNetForMultiLabelSequenceClassification(torch.nn.Module):
def __init__(self, num_labels=2):
super(XLNetForMultiLabelSequenceClassification, self).__init__()
self.num_labels = num_labels
self.xlnet = XLNetModel.from_pretrained('xlnet-base-cased')
self.classifier = torch.nn.Linear(768, num_labels)
torch.nn.init.xavier_normal_(self.classifier.weight)
def forward(self, input_ids, token_type_ids=None,\
attention_mask=None, labels=None):
# last hidden layer
last_hidden_state = self.xlnet(input_ids=input_ids,\
attention_mask=attention_mask,\
token_type_ids=token_type_ids
)
# pool the outputs into a mean vector
mean_last_hidden_state = self.pool_hidden_state(last_hidden_state)
logits = self.classifier(mean_last_hidden_state)
logits = logits[:, 1] - logits[:, 0]
if labels is not None:
loss = BCEWithLogitsLoss()(logits, labels.float())
#
return loss
else:
return logits
def freeze_xlnet_decoder(self):
"""
Freeze XLNet weight parameters. They will not be updated during training.
"""
for param in self.xlnet.parameters():
param.requires_grad = False
def unfreeze_xlnet_decoder(self):
"""
Unfreeze XLNet weight parameters. They will be updated during training.
"""
for param in self.xlnet.parameters():
param.requires_grad = True
def pool_hidden_state(self, last_hidden_state):
"""
Pool the output vectors into a single mean vector
"""
last_hidden_state = last_hidden_state[0]
mean_last_hidden_state = torch.mean(last_hidden_state, 1)
return mean_last_hidden_state
model = XLNetForMultiLabelSequenceClassification(num_labels=len(labels.unique()))
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=760.0, style=ProgressStyle(description_…
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=467042463.0, style=ProgressStyle(descri…
AdamW is a huggingface transformer class wrapper of AdamW, the Decoupled Weight Decay algorithm. An optimizer with weight decay fixed that can be used to fine-tuned models, and
several schedules in the form of schedule objects and gradient accumulation of multiple batches.
PyTorch has similar implementation in the optim package.
torch.optim is a PyTorch package that implements various optimization algorithms.
torch.optim.AdamW : Implements AdamW algorithm. The original Adam algorithm was proposed in Adam: A Method for Stochastic Optimization. The AdamW variant was proposed in Decoupled Weight Decay Regularization. The paper for this algorithm is found
here.
Generally, fine tuning parameters use a smaller learning rate, while training the output layer from scratch can use a larger learning rate.
#optimizer = AdamW(model.parameters(),
# lr = 2e-5, # args.learning_rate - default is 5e-5
# # eps = 1e-8 # args.adam_epsilon - default is 1e-8.
# weight_decay=0.01,
# correct_bias=False
# )
#
# scheduler = WarmupLinearSchedule(optimizer, warmup_steps=num_warmup_steps, t_total=num_total_steps) # PyTorch scheduler
# replace AdamW with Adafactor
#optimizer = Adafactor(model.parameters(), scale_parameter=True, relative_step=True, warmup_init=True, lr=None)
#import torch
#import torch.optim
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay':0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5)
# replace AdamW with Adafactor
#optimizer = Adafactor(
# model.parameters(),
# lr=1e-5,
# eps=(1e-30, 1e-3),
#clip_threshold=1.0,
#decay_rate=-0.8,
#beta1=None,
#weight_decay=0.01,
#relative_step=False,
#scale_parameter=False,
#warmup_init=False
#)
The training loop together with model validation is done below. The main steps invloved here is for each pass in our loop we have a training phase and a validation phase. At each pass we need to:
Training loop:
- Tell the model to compute gradients by setting the model in train mode
- Unpack our data inputs and labels
- Load data onto the GPU for acceleration
- Clear out the gradients calculated in the previous pass. In pytorch the gradients accumulate by default (useful for things like RNNs) unless you explicitly clear them out
- Forward pass (feed input data through the network)
- Backward pass (backpropagation)
- Tell the network to update parameters with optimizer.step()
- Track variables for monitoring progress Evalution loop:
Tell the model not to compute gradients by setting th emodel in evaluation mode
- Unpack our data inputs and labels
- Load data onto the GPU for acceleration
- Forward pass (feed input data through the network)
- Compute loss on our validation data and track variables for monitoring progress
def train(model, num_epochs,\
optimizer,\
train_dataloader, valid_dataloader,\
model_save_path,\
train_loss_set=[], valid_loss_set = [],\
lowest_eval_loss=None, start_epoch=0,\
device="cpu"
):
"""
Train the model and save the model with the lowest validation loss
"""
# We'll store a number of quantities such as training and validation loss,
# validation accuracy, and timings.
training_stats = []
# Measure the total training time for the whole run.
total_t0 = time.time()
model.to(device)
# trange is a tqdm wrapper around the python range function
for i in trange(num_epochs, desc="Epoch"):
# if continue training from saved model
actual_epoch = start_epoch + i
# ========================================
# Training
# ========================================
# Perform one full pass over the training set.
print("")
print('======== Epoch {:} / {:} ========'.format(actual_epoch, num_epochs))
print('Training...')
# Measure how long the training epoch takes.
t0 = time.time()
# Set our model to training mode (as opposed to evaluation mode)
model.train()
# Tracking variables
tr_loss = 0
num_train_samples = 0
# Train the data for one epoch
for step, batch in enumerate(train_dataloader):
# Progress update every 40 batches.
if step % 40 == 0 and not step == 0:
# Calculate elapsed time in minutes.
elapsed = format_time(time.time() - t0)
# Report progress.
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Clear out the gradients (by default they accumulate)
optimizer.zero_grad()
# Forward pass
loss = model(input_ids=b_input_ids, attention_mask=b_input_mask, labels=b_labels)
# store train loss
tr_loss += loss.item()
num_train_samples += b_labels.size(0)
# Backward pass
loss.backward()
# Update parameters and take a step using the computed gradient
optimizer.step()
#scheduler.step()
# Update tracking variables
epoch_train_loss = tr_loss/num_train_samples
train_loss_set.append(epoch_train_loss)
# print("Train loss: {}".format(epoch_train_loss))
# Measure how long this epoch took.
training_time = format_time(time.time() - t0)
print("")
print(" Average training loss: {0:.2f}".format(epoch_train_loss))
print(" Training epcoh took: {:}".format(training_time))
# ========================================
# Validation
# ========================================
# After the completion of each training epoch, measure our performance on
# our validation set.
# After the completion of each training epoch, measure our performance on
# our validation set.
print("")
print("Running Validation...")
t0 = time.time()
# Put model in evaluation mode to evaluate loss on the validation set
model.eval()
# Tracking variables
eval_loss = 0
num_eval_samples = 0
# Evaluate data for one epoch
for batch in valid_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients,
# saving memory and speeding up validation
with torch.no_grad():
# Forward pass, calculate validation loss
loss = model(input_ids=b_input_ids, attention_mask=b_input_mask, labels=b_labels)
# store valid loss
eval_loss += loss.item()
num_eval_samples += b_labels.size(0)
epoch_eval_loss = eval_loss/num_eval_samples
valid_loss_set.append(epoch_eval_loss)
# print("Valid loss: {}".format(epoch_eval_loss))
# Report the final accuracy for this validation run.
# avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)
# print(" Accuracy: {0:.2f}".format(avg_val_accuracy))
# Calculate the average loss over all of the batches.
# avg_val_loss = total_eval_loss / len(validation_dataloader)
# Measure how long the validation run took.
validation_time = format_time(time.time() - t0)
print(" Validation Loss: {0:.2f}".format(epoch_eval_loss))
print(" Validation took: {:}".format(validation_time))
# Record all statistics from this epoch.
training_stats.append(
{
'epoch': actual_epoch,
'Training Loss': epoch_train_loss,
'Valid. Loss': epoch_eval_loss,
# 'Valid. Accur.': avg_val_accuracy,
'Training Time': training_time,
'Validation Time': validation_time
}
)
if lowest_eval_loss == None:
lowest_eval_loss = epoch_eval_loss
# save model
save_model(model, model_save_path, actual_epoch,\
lowest_eval_loss, train_loss_set, valid_loss_set)
else:
if epoch_eval_loss < lowest_eval_loss:
lowest_eval_loss = epoch_eval_loss
# save model
save_model(model, model_save_path, actual_epoch,\
lowest_eval_loss, train_loss_set, valid_loss_set)
print("")
print("Training complete!")
print("Total training took {:} (h:mm:ss)".format(format_time(time.time()-total_t0)))
return model, train_loss_set, valid_loss_set, training_stats
import time
import datetime
def format_time(elapsed):
'''
Takes a time in seconds and returns a string hh:mm:ss
'''
# Round to the nearest second.
elapsed_rounded = int(round((elapsed)))
# Format as hh:mm:ss
return str(datetime.timedelta(seconds=elapsed_rounded))
save_path = '/content/drive/MyDrive/Colab Notebooks/NLP/HuggingFace/XLNET/'
# function to save and load the model form a specific epoch
def save_model(model, save_path, epochs, lowest_eval_loss, train_loss_hist, valid_loss_hist):
"""
Save the model to the path directory provided
"""
model_to_save = model.module if hasattr(model, 'module') else model
checkpoint = {'epochs': epochs, \
'lowest_eval_loss': lowest_eval_loss,\
'state_dict': model_to_save.state_dict(),\
'train_loss_hist': train_loss_hist,\
'valid_loss_hist': valid_loss_hist,\
'optimizer_state_dict': optimizer.state_dict()
}
torch.save(checkpoint, save_path)
print("Saving model at epoch {} with validation loss of {}".format(epochs,\
lowest_eval_loss))
return
def load_model(save_path):
"""
Load the model from the path directory provided
"""
checkpoint = torch.load(save_path)
model_state_dict = checkpoint['state_dict']
model = XLNetForMultiLabelSequenceClassification(num_labels=model_state_dict["classifier.weight"].size()[0])
model.load_state_dict(model_state_dict)
epochs = checkpoint["epochs"]
lowest_eval_loss = checkpoint["lowest_eval_loss"]
train_loss_hist = checkpoint["train_loss_hist"]
valid_loss_hist = checkpoint["valid_loss_hist"]
return model, epochs, lowest_eval_loss, train_loss_hist, valid_loss_hist
torch.cuda.empty_cache()
num_epochs = 5
cwd = os.getcwd()
model_save_path = output_model_file = "/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/xlnet.bin"
model, train_loss_set, valid_loss_set, training_stats = train(model=model,\
num_epochs=num_epochs,\
optimizer=optimizer,\
train_dataloader=train_dataloader,\
valid_dataloader=validation_dataloader,\
model_save_path=model_save_path,\
device="cuda"
)
Epoch: 0%| | 0/5 [00:00<?, ?it/s]
======== Epoch 0 / 5 ========
Training...
/usr/local/lib/python3.7/dist-packages/transformers/optimization.py:155: UserWarning:
This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at /pytorch/torch/csrc/utils/python_arg_parser.cpp:1005.)
Batch 40 of 1,796. Elapsed: 0:00:18.
Batch 80 of 1,796. Elapsed: 0:00:36.
Batch 120 of 1,796. Elapsed: 0:00:55.
Batch 160 of 1,796. Elapsed: 0:01:13.
Batch 200 of 1,796. Elapsed: 0:01:32.
Batch 240 of 1,796. Elapsed: 0:01:51.
Batch 280 of 1,796. Elapsed: 0:02:11.
Batch 320 of 1,796. Elapsed: 0:02:31.
Batch 360 of 1,796. Elapsed: 0:02:50.
Batch 400 of 1,796. Elapsed: 0:03:10.
Batch 440 of 1,796. Elapsed: 0:03:31.
Batch 480 of 1,796. Elapsed: 0:03:50.
Batch 520 of 1,796. Elapsed: 0:04:10.
Batch 560 of 1,796. Elapsed: 0:04:30.
Batch 600 of 1,796. Elapsed: 0:04:51.
Batch 640 of 1,796. Elapsed: 0:05:11.
Batch 680 of 1,796. Elapsed: 0:05:31.
Batch 720 of 1,796. Elapsed: 0:05:51.
Batch 760 of 1,796. Elapsed: 0:06:11.
Batch 800 of 1,796. Elapsed: 0:06:31.
Batch 840 of 1,796. Elapsed: 0:06:52.
Batch 880 of 1,796. Elapsed: 0:07:13.
Batch 920 of 1,796. Elapsed: 0:07:33.
Batch 960 of 1,796. Elapsed: 0:07:54.
Batch 1,000 of 1,796. Elapsed: 0:08:14.
Batch 1,040 of 1,796. Elapsed: 0:08:34.
Batch 1,080 of 1,796. Elapsed: 0:08:55.
Batch 1,120 of 1,796. Elapsed: 0:09:15.
Batch 1,160 of 1,796. Elapsed: 0:09:36.
Batch 1,200 of 1,796. Elapsed: 0:09:56.
Batch 1,240 of 1,796. Elapsed: 0:10:17.
Batch 1,280 of 1,796. Elapsed: 0:10:37.
Batch 1,320 of 1,796. Elapsed: 0:10:58.
Batch 1,360 of 1,796. Elapsed: 0:11:18.
Batch 1,400 of 1,796. Elapsed: 0:11:39.
Batch 1,440 of 1,796. Elapsed: 0:11:59.
Batch 1,480 of 1,796. Elapsed: 0:12:20.
Batch 1,520 of 1,796. Elapsed: 0:12:40.
Batch 1,560 of 1,796. Elapsed: 0:13:01.
Batch 1,600 of 1,796. Elapsed: 0:13:21.
Batch 1,640 of 1,796. Elapsed: 0:13:42.
Batch 1,680 of 1,796. Elapsed: 0:14:03.
Batch 1,720 of 1,796. Elapsed: 0:14:23.
Batch 1,760 of 1,796. Elapsed: 0:14:44.
Average training loss: 0.00
Training epcoh took: 0:15:02
Running Validation...
Validation Loss: 0.00
Validation took: 0:01:22
Epoch: 20%|██ | 1/5 [16:41<1:06:44, 1001.08s/it]
Saving model at epoch 0 with validation loss of 0.00033740604524109483
======== Epoch 1 / 5 ========
Training...
Batch 40 of 1,796. Elapsed: 0:00:20.
Batch 80 of 1,796. Elapsed: 0:00:41.
Batch 120 of 1,796. Elapsed: 0:01:01.
Batch 160 of 1,796. Elapsed: 0:01:22.
Batch 200 of 1,796. Elapsed: 0:01:42.
Batch 240 of 1,796. Elapsed: 0:02:03.
Batch 280 of 1,796. Elapsed: 0:02:23.
Batch 320 of 1,796. Elapsed: 0:02:44.
Batch 360 of 1,796. Elapsed: 0:03:04.
Batch 400 of 1,796. Elapsed: 0:03:25.
Batch 440 of 1,796. Elapsed: 0:03:45.
Batch 480 of 1,796. Elapsed: 0:04:06.
Batch 520 of 1,796. Elapsed: 0:04:27.
Batch 560 of 1,796. Elapsed: 0:04:47.
Batch 600 of 1,796. Elapsed: 0:05:08.
Batch 640 of 1,796. Elapsed: 0:05:28.
Batch 680 of 1,796. Elapsed: 0:05:49.
Batch 720 of 1,796. Elapsed: 0:06:09.
Batch 760 of 1,796. Elapsed: 0:06:30.
Batch 800 of 1,796. Elapsed: 0:06:50.
Batch 840 of 1,796. Elapsed: 0:07:11.
Batch 880 of 1,796. Elapsed: 0:07:31.
Batch 920 of 1,796. Elapsed: 0:07:52.
Batch 960 of 1,796. Elapsed: 0:08:12.
Batch 1,000 of 1,796. Elapsed: 0:08:33.
Batch 1,040 of 1,796. Elapsed: 0:08:53.
Batch 1,080 of 1,796. Elapsed: 0:09:14.
Batch 1,120 of 1,796. Elapsed: 0:09:35.
Batch 1,160 of 1,796. Elapsed: 0:09:55.
Batch 1,200 of 1,796. Elapsed: 0:10:16.
Batch 1,240 of 1,796. Elapsed: 0:10:36.
Batch 1,280 of 1,796. Elapsed: 0:10:57.
Batch 1,320 of 1,796. Elapsed: 0:11:17.
Batch 1,360 of 1,796. Elapsed: 0:11:38.
Batch 1,400 of 1,796. Elapsed: 0:11:59.
Batch 1,440 of 1,796. Elapsed: 0:12:19.
Batch 1,480 of 1,796. Elapsed: 0:12:39.
Batch 1,520 of 1,796. Elapsed: 0:13:00.
Batch 1,560 of 1,796. Elapsed: 0:13:20.
Batch 1,600 of 1,796. Elapsed: 0:13:40.
Batch 1,640 of 1,796. Elapsed: 0:14:01.
Batch 1,680 of 1,796. Elapsed: 0:14:21.
Batch 1,720 of 1,796. Elapsed: 0:14:42.
Batch 1,760 of 1,796. Elapsed: 0:15:03.
Average training loss: 0.00
Training epcoh took: 0:15:21
Running Validation...
Epoch: 40%|████ | 2/5 [33:24<50:05, 1001.67s/it]
Validation Loss: 0.00
Validation took: 0:01:22
======== Epoch 2 / 5 ========
Training...
Batch 40 of 1,796. Elapsed: 0:00:21.
Batch 80 of 1,796. Elapsed: 0:00:41.
Batch 120 of 1,796. Elapsed: 0:01:02.
Batch 160 of 1,796. Elapsed: 0:01:22.
Batch 200 of 1,796. Elapsed: 0:01:42.
Batch 240 of 1,796. Elapsed: 0:02:03.
Batch 280 of 1,796. Elapsed: 0:02:23.
Batch 320 of 1,796. Elapsed: 0:02:44.
Batch 360 of 1,796. Elapsed: 0:03:04.
Batch 400 of 1,796. Elapsed: 0:03:25.
Batch 440 of 1,796. Elapsed: 0:03:45.
Batch 480 of 1,796. Elapsed: 0:04:06.
Batch 520 of 1,796. Elapsed: 0:04:26.
Batch 560 of 1,796. Elapsed: 0:04:47.
Batch 600 of 1,796. Elapsed: 0:05:08.
Batch 640 of 1,796. Elapsed: 0:05:28.
Batch 680 of 1,796. Elapsed: 0:05:49.
Batch 720 of 1,796. Elapsed: 0:06:09.
Batch 760 of 1,796. Elapsed: 0:06:30.
Batch 800 of 1,796. Elapsed: 0:06:50.
Batch 840 of 1,796. Elapsed: 0:07:11.
Batch 880 of 1,796. Elapsed: 0:07:31.
Batch 920 of 1,796. Elapsed: 0:07:52.
Batch 960 of 1,796. Elapsed: 0:08:13.
Batch 1,000 of 1,796. Elapsed: 0:08:33.
Batch 1,040 of 1,796. Elapsed: 0:08:54.
Batch 1,080 of 1,796. Elapsed: 0:09:14.
Batch 1,120 of 1,796. Elapsed: 0:09:35.
Batch 1,160 of 1,796. Elapsed: 0:09:55.
Batch 1,200 of 1,796. Elapsed: 0:10:16.
Batch 1,240 of 1,796. Elapsed: 0:10:36.
Batch 1,280 of 1,796. Elapsed: 0:10:57.
Batch 1,320 of 1,796. Elapsed: 0:11:17.
Batch 1,360 of 1,796. Elapsed: 0:11:38.
Batch 1,400 of 1,796. Elapsed: 0:11:58.
Batch 1,440 of 1,796. Elapsed: 0:12:19.
Batch 1,480 of 1,796. Elapsed: 0:12:39.
Batch 1,520 of 1,796. Elapsed: 0:13:00.
Batch 1,560 of 1,796. Elapsed: 0:13:20.
Batch 1,600 of 1,796. Elapsed: 0:13:41.
Batch 1,640 of 1,796. Elapsed: 0:14:01.
Batch 1,680 of 1,796. Elapsed: 0:14:22.
Batch 1,720 of 1,796. Elapsed: 0:14:42.
Batch 1,760 of 1,796. Elapsed: 0:15:03.
Average training loss: 0.00
Training epcoh took: 0:15:21
Running Validation...
Epoch: 60%|██████ | 3/5 [50:07<33:24, 1002.10s/it]
Validation Loss: 0.00
Validation took: 0:01:22
======== Epoch 3 / 5 ========
Training...
Batch 40 of 1,796. Elapsed: 0:00:21.
Batch 80 of 1,796. Elapsed: 0:00:41.
Batch 120 of 1,796. Elapsed: 0:01:02.
Batch 160 of 1,796. Elapsed: 0:01:22.
Batch 200 of 1,796. Elapsed: 0:01:43.
Batch 240 of 1,796. Elapsed: 0:02:03.
Batch 280 of 1,796. Elapsed: 0:02:24.
Batch 320 of 1,796. Elapsed: 0:02:45.
Batch 360 of 1,796. Elapsed: 0:03:05.
Batch 400 of 1,796. Elapsed: 0:03:26.
Batch 440 of 1,796. Elapsed: 0:03:47.
Batch 480 of 1,796. Elapsed: 0:04:07.
Batch 520 of 1,796. Elapsed: 0:04:28.
Batch 560 of 1,796. Elapsed: 0:04:48.
Batch 600 of 1,796. Elapsed: 0:05:09.
Batch 640 of 1,796. Elapsed: 0:05:30.
Batch 680 of 1,796. Elapsed: 0:05:50.
Batch 720 of 1,796. Elapsed: 0:06:11.
Batch 760 of 1,796. Elapsed: 0:06:31.
Batch 800 of 1,796. Elapsed: 0:06:52.
Batch 840 of 1,796. Elapsed: 0:07:12.
Batch 880 of 1,796. Elapsed: 0:07:33.
Batch 920 of 1,796. Elapsed: 0:07:53.
Batch 960 of 1,796. Elapsed: 0:08:14.
Batch 1,000 of 1,796. Elapsed: 0:08:34.
Batch 1,040 of 1,796. Elapsed: 0:08:55.
Batch 1,080 of 1,796. Elapsed: 0:09:15.
Batch 1,120 of 1,796. Elapsed: 0:09:36.
Batch 1,160 of 1,796. Elapsed: 0:09:56.
Batch 1,200 of 1,796. Elapsed: 0:10:17.
Batch 1,240 of 1,796. Elapsed: 0:10:37.
Batch 1,280 of 1,796. Elapsed: 0:10:58.
Batch 1,320 of 1,796. Elapsed: 0:11:18.
Batch 1,360 of 1,796. Elapsed: 0:11:39.
Batch 1,400 of 1,796. Elapsed: 0:11:59.
Batch 1,440 of 1,796. Elapsed: 0:12:20.
Batch 1,480 of 1,796. Elapsed: 0:12:41.
Batch 1,520 of 1,796. Elapsed: 0:13:01.
Batch 1,560 of 1,796. Elapsed: 0:13:22.
Batch 1,600 of 1,796. Elapsed: 0:13:42.
Batch 1,640 of 1,796. Elapsed: 0:14:03.
Batch 1,680 of 1,796. Elapsed: 0:14:24.
Batch 1,720 of 1,796. Elapsed: 0:14:44.
Batch 1,760 of 1,796. Elapsed: 0:15:05.
Average training loss: 0.00
Training epcoh took: 0:15:23
Running Validation...
Epoch: 80%|████████ | 4/5 [1:06:52<16:43, 1003.06s/it]
Validation Loss: 0.00
Validation took: 0:01:22
======== Epoch 4 / 5 ========
Training...
Batch 40 of 1,796. Elapsed: 0:00:21.
Batch 80 of 1,796. Elapsed: 0:00:41.
Batch 120 of 1,796. Elapsed: 0:01:02.
Batch 160 of 1,796. Elapsed: 0:01:22.
Batch 200 of 1,796. Elapsed: 0:01:43.
Batch 240 of 1,796. Elapsed: 0:02:04.
Batch 280 of 1,796. Elapsed: 0:02:24.
Batch 320 of 1,796. Elapsed: 0:02:45.
Batch 360 of 1,796. Elapsed: 0:03:05.
Batch 400 of 1,796. Elapsed: 0:03:26.
Batch 440 of 1,796. Elapsed: 0:03:46.
Batch 480 of 1,796. Elapsed: 0:04:07.
Batch 520 of 1,796. Elapsed: 0:04:28.
Batch 560 of 1,796. Elapsed: 0:04:48.
Batch 600 of 1,796. Elapsed: 0:05:09.
Batch 640 of 1,796. Elapsed: 0:05:30.
Batch 680 of 1,796. Elapsed: 0:05:50.
Batch 720 of 1,796. Elapsed: 0:06:11.
Batch 760 of 1,796. Elapsed: 0:06:31.
Batch 800 of 1,796. Elapsed: 0:06:52.
Batch 840 of 1,796. Elapsed: 0:07:13.
Batch 880 of 1,796. Elapsed: 0:07:33.
Batch 920 of 1,796. Elapsed: 0:07:54.
Batch 960 of 1,796. Elapsed: 0:08:15.
Batch 1,000 of 1,796. Elapsed: 0:08:35.
Batch 1,040 of 1,796. Elapsed: 0:08:56.
Batch 1,080 of 1,796. Elapsed: 0:09:16.
Batch 1,120 of 1,796. Elapsed: 0:09:37.
Batch 1,160 of 1,796. Elapsed: 0:09:57.
Batch 1,200 of 1,796. Elapsed: 0:10:18.
Batch 1,240 of 1,796. Elapsed: 0:10:38.
Batch 1,280 of 1,796. Elapsed: 0:10:58.
Batch 1,320 of 1,796. Elapsed: 0:11:19.
Batch 1,360 of 1,796. Elapsed: 0:11:39.
Batch 1,400 of 1,796. Elapsed: 0:12:00.
Batch 1,440 of 1,796. Elapsed: 0:12:20.
Batch 1,480 of 1,796. Elapsed: 0:12:41.
Batch 1,520 of 1,796. Elapsed: 0:13:01.
Batch 1,560 of 1,796. Elapsed: 0:13:22.
Batch 1,600 of 1,796. Elapsed: 0:13:42.
Batch 1,640 of 1,796. Elapsed: 0:14:03.
Batch 1,680 of 1,796. Elapsed: 0:14:24.
Batch 1,720 of 1,796. Elapsed: 0:14:44.
Batch 1,760 of 1,796. Elapsed: 0:15:05.
Average training loss: 0.00
Training epcoh took: 0:15:23
Running Validation...
Epoch: 100%|██████████| 5/5 [1:23:37<00:00, 1003.59s/it]
Validation Loss: 0.00
Validation took: 0:01:22
Training complete!
Total training took 1:23:48 (h:mm:ss)
Alternatively, the model checkpoint can also be saved a .ckpt file as shown below.
When saving a model for inference, it is only necessary to save the trained model’s learned parameters. Saving the model’s state_dict with the torch.save() function will give you the most flexibility for restoring the model later, which is why it is the recommended method for saving models.
A common PyTorch convention is to save models using either a .pt or .pth file extension.
Remember that you must call model.eval() to set dropout and batch normalization layers to evaluation mode before running inference. Failing to do this will yield inconsistent inference results.
#os.listdir('/content/drive/MyDrive/Colab Notebooks/NLP/XLNET')
#model = load_model("/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/xlnet.bin")
#save_path = '/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/xlnet.pth'
#torch.save({
# 'epoch': epoch,
# 'model_state_dict': model.state_dict(),
# 'optimizer_state_dict': optimizer.state_dict(),
# 'loss': loss,
# ...
# }, save_path)
#
#model = TheModelClass(*args, **kwargs)
#model = XLNetForMultiLabelSequenceClassification(num_labels=len(labels.unique()))
#optimizer = TheOptimizerClass(*args, **kwargs)
#checkpoint = torch.load(save_path)
#model.load_state_dict(checkpoint['model_state_dict'])
#optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
#epoch = checkpoint['epoch']
#loss = checkpoint['loss']
#model.eval()
# - or -
#model.train()
#A common PyTorch convention is to save models using either a .pt or .pth file extension.
#saving method which works
save_path = '/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/xlnet.pth'
torch.save(model.state_dict(), save_path)
device = torch.device("cuda")
#model = TheModelClass(*args, **kwargs)
model = XLNetForMultiLabelSequenceClassification(num_labels=len(labels.unique()))
model.load_state_dict(torch.load(save_path))
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model
XLNetForMultiLabelSequenceClassification(
(xlnet): XLNetModel(
(word_embedding): Embedding(32000, 768)
(layer): ModuleList(
(0): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(1): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(2): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(3): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(4): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(5): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(6): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(7): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(8): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(9): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(10): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(11): XLNetLayer(
(rel_attn): XLNetRelativeAttention(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): XLNetFeedForward(
(layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layer_1): Linear(in_features=768, out_features=3072, bias=True)
(layer_2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
####4.2 Training Evaluation
import pandas as pd
# Display floats with two decimal places.
pd.set_option('precision', 2)
# Create a DataFrame from our training statistics.
df_stats = pd.DataFrame(data=training_stats)
# Use the 'epoch' as the row index.
df_stats = df_stats.set_index('epoch')
# Display the table.
df_stats
| Training Loss | Valid. Loss | Training Time | Validation Time | |
|---|---|---|---|---|
| epoch | ||||
| 0 | 1.54e-03 | 3.37e-04 | 0:15:02 | 0:01:22 |
| 1 | 5.45e-04 | 5.72e-04 | 0:15:21 | 0:01:22 |
| 2 | 6.36e-04 | 1.32e-03 | 0:15:21 | 0:01:22 |
| 3 | 6.01e-04 | 8.76e-04 | 0:15:23 | 0:01:22 |
| 4 | 4.10e-04 | 3.55e-04 | 0:15:23 | 0:01:22 |
# Plot loss
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# Use plot styling from seaborn.
sns.set(style='darkgrid')
# Increase the plot size and font size.
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12,6)
# Plot the learning curve.
plt.plot(df_stats['Training Loss'], 'b-o', label="Training")
plt.plot(df_stats['Valid. Loss'], 'g-o', label="Validation")
# Label the plot.
plt.title("Training & Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.xticks([0, 1, 2, 3, 4, 5])
plt.savefig('/content/drive/MyDrive/Colab Notebooks/NLP/XLNET/file3.png')
plt.show()
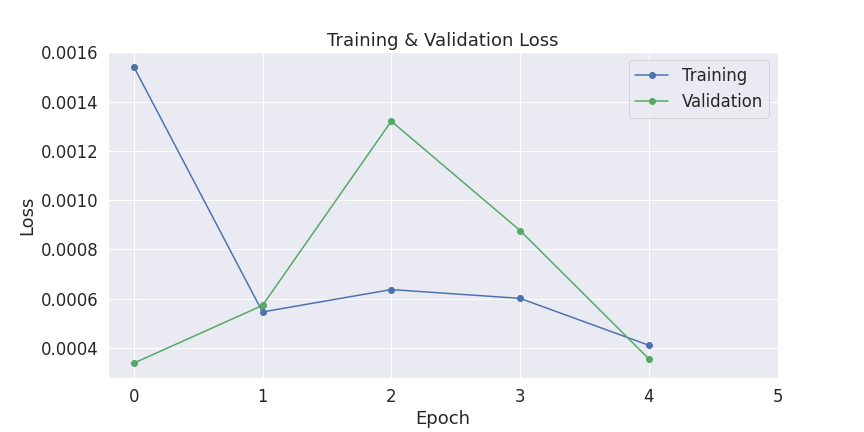
####6. Get Predictions
# Cleaning text
test['text_cleaned'] = list(map(lambda x: preprocess_sentence_english(x),test['text']) )
# Get the lists of sentences and their labels
sentences = test.text_cleaned.values
# input_ids = torch.from_numpy(input_ids)
# attention_masks = torch.tensor(attention_masks)
# labels = torch.tensor(labels)
test_input_ids = tokenize_inputs(sentences, tokenizer, num_embeddings=120)
test_attention_masks = create_attn_masks(test_input_ids)
test["features"] = test_input_ids.tolist()
test["masks"] = test_attention_masks
def generate_predictions(model, df, device="cpu", batch_size=16):
num_iter = math.ceil(df.shape[0]/batch_size)
pred_probs = []
#model.to(device)
#model.eval()
for i in range(num_iter):
df_subset = df.iloc[i*batch_size:(i+1)*batch_size,:]
X = df_subset["features"].values.tolist()
masks = df_subset["masks"].values.tolist()
X = torch.tensor(X)
masks = torch.tensor(masks, dtype=torch.long)
X = X.to(device)
masks = masks.to(device)
with torch.no_grad():
logits = model(input_ids=X, attention_mask=masks)
logits = logits.sigmoid().detach().cpu().numpy()
# pred_probs = np.vstack([pred_probs, logits])
pred_probs.extend(logits.tolist())
return pred_probs
predicted probabilities for real or fake news on the test set.
pred_probs = generate_predictions(model, test, device="cuda", batch_size=16)
# pred_probs
import statistics
statistics.mean(pred_probs)
0.4804657323873718
test['target'] = pred_probs
test['target'] = np.array(test['target'] >= 0.5, dtype='int')
#test[['id', 'target']].to_csv('submission.csv', index=False)
auc_value = roc_auc_score(test['label'], np.asarray(pred_probs) >0.5)
print("auc on test {}".format(auc_value))
#type(pred_probs)
auc on test 0.9978233756695014
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score,precision_recall_curve
from sklearn.metrics import precision_recall_fscore_support
from numpy import trapz
from scipy.integrate import simps
from sklearn.metrics import f1_score
from sklearn.metrics import roc_curve, roc_auc_score,balanced_accuracy_score
from sklearn.metrics import average_precision_score,cohen_kappa_score
def Evaluate(labels, predictions, p=0.5):
CM= confusion_matrix(labels, predictions > p)
TN = CM[0][0]
FN = CM[1][0]
TP = CM[1][1]
FP = CM[0][1]
print(' (True Negatives): {}'.format(TN))
print(' (False Negatives): {}'.format(FN))
print(' (True Positives): {}'.format(TP))
print('(False Positives):{}'.format(FP))
print('Total positive : ', np.sum(CM[1]))
auc = roc_auc_score(labels, predictions)
prec=precision_score(labels, predictions>0.5)
rec=recall_score(labels, predictions>0.5)
# calculate F1 score
f1 = f1_score(labels, predictions>p)
print('auc :{}'.format(auc))
print('precision :{}'.format(prec))
print('recall :{}'.format(rec))
print('f1 :{}'.format(f1))
# Compute Precision-Recall and plot curve
precision, recall, thresholds = precision_recall_curve(labels, predictions >0.5)
#use the trapezoidal rule to calculate the area under the precion-recall curve
area = trapz(recall, precision)
#area = simps(recall, precision)
print("Area Under Precision Recall Curve(AP): %0.4f" % area) #should be same as AP?
average_precision = average_precision_score(labels, predictions>0.5)
print("average precision: %0.4f" % average_precision)
kappa = cohen_kappa_score(labels, predictions>0.5)
print('kappa :{}'.format(kappa))
balanced_accuracy = balanced_accuracy_score(labels, predictions>0.5)
print('balanced_accuracy :{}'.format(balanced_accuracy))
Evaluate(test['label'], np.asarray(pred_probs) >0.5)
(True Negatives): 4665
(False Negatives): 16
(True Positives): 4296
(False Positives):3
Total positive : 4312
auc :0.9978233756695014
precision :0.9993021632937893
recall :0.9962894248608535
f1 :0.997793519916386
Area Under Precision Recall Curve(AP): 0.5185
average precision: 0.9974
kappa :0.9957612258946119
balanced_accuracy :0.9978233756695013
Sections of the code used here was obtained thanks to Jaskaran Singh notebook on kaggle.