Introduction
Fake news include false news stories,disinformation and misinformation with the intent of misleading people. The proliferation of fake news in recent years poses great danger to the safety and security of many people around the world. Some people have acted on fake news to commit certain crimes which are unpardonable. The growth of the internet and social media around the world has helped to explode the consumption of fake news and conspiracy theories around the world. Determining if a piece of news item is fake or real is not so obvious these days especially when the perpetrators create websites with similar names like well-known authentic news outlets. In this post we will try to do in-depth exploratory analysis and comparison of real and fake new. We will look at negativity, positivity and neutrality in sentiments expressed in both fake and real news. We would end by demonstrating how we can predict whether a news item is fake or real with a classification model.
The dataset for this analysis is located on kaggle. Find the link here.
#!pip install gensim # Gensim is an open-source library for unsupervised topic modeling and natural language processing
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
import nltk
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
from nltk.stem import SnowballStemmer
from nltk.stem import WordNetLemmatizer
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud, STOPWORDS
import re
from nltk.corpus import stopwords
import seaborn as sns
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
import matplotlib.pyplot as plt
import plotly
import seaborn as sns
from plotly import graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrix
from tqdm import tqdm
import itertools
import collections
from xgboost import XGBClassifier
import xgboost as xgb
%matplotlib inline
%autosave 5
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package wordnet to /root/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
Autosaving every 5 seconds
import warnings
warnings.filterwarnings("ignore")
from tqdm.notebook import tqdm
tqdm.pandas(desc="Completed") # add progressbar to pandas, use progress_apply instead apply
import plotly.figure_factory as ff
import plotly.graph_objects as go
import plotly.express as px
from ipywidgets import interact #interactive plots
from IPython.display import clear_output
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
!unzip /content/drive/MyDrive/Data/Fake_True_News.zip
True_data = pd.read_csv('True.csv')
True_data['label']= 1
Fake_data = pd.read_csv('Fake.csv')
Fake_data['label']=0
True_data.head()
Archive: /content/drive/MyDrive/Data/Fake_True_News.zip
replace Fake.csv? [y]es, [n]o, [A]ll, [N]one, [r]ename: yes
inflating: Fake.csv
replace True.csv? [y]es, [n]o, [A]ll, [N]one, [r]ename: yes
inflating: True.csv
| title | text | subject | date | label | |
|---|---|---|---|---|---|
| 0 | As U.S. budget fight looms, Republicans flip t... | WASHINGTON (Reuters) - The head of a conservat... | politicsNews | December 31, 2017 | 1 |
| 1 | U.S. military to accept transgender recruits o... | WASHINGTON (Reuters) - Transgender people will... | politicsNews | December 29, 2017 | 1 |
| 2 | Senior U.S. Republican senator: 'Let Mr. Muell... | WASHINGTON (Reuters) - The special counsel inv... | politicsNews | December 31, 2017 | 1 |
| 3 | FBI Russia probe helped by Australian diplomat... | WASHINGTON (Reuters) - Trump campaign adviser ... | politicsNews | December 30, 2017 | 1 |
| 4 | Trump wants Postal Service to charge 'much mor... | SEATTLE/WASHINGTON (Reuters) - President Donal... | politicsNews | December 29, 2017 | 1 |
df = pd.concat([True_data,Fake_data],axis=0)
print(df.shape)
print(type(df.label))
df.info()
(44898, 5)
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 44898 entries, 0 to 23480
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 44898 non-null object
1 text 44898 non-null object
2 subject 44898 non-null object
3 date 44898 non-null object
4 label 44898 non-null int64
dtypes: int64(1), object(4)
memory usage: 2.1+ MB
#df= df.sample(frac=0.1)
df.shape
(44898, 5)
# Create and register a new `tqdm` instance with `pandas`
# (can use tqdm_gui, optional kwargs, etc.)
tqdm.pandas()
#df["title"] = df["title"].progress_apply(preprocess)
#df["text"] = df["text"].progress_apply(preprocess)
from sklearn.utils import shuffle
df = shuffle(df)
df.head()
| title | text | subject | date | label | |
|---|---|---|---|---|---|
| 13936 | FORMER MEXICAN PREZ Sends “Middle Finger” To T... | Wow these sound exactly like the type of peopl... | politics | May 10, 2016 | 0 |
| 10132 | OOPS! NY GOV CUOMO Announces Statues of Confed... | Really Andrew? Does all of New York really sta... | politics | Aug 17, 2017 | 0 |
| 7518 | Janet Reno, first U.S. woman attorney general,... | (Reuters) - Blunt-spoken Janet Reno, who serve... | politicsNews | November 7, 2016 | 1 |
| 17792 | Murdered North Korean Kim Jong Nam had $100,00... | KUALA LUMPUR (Reuters) - The half-brother of N... | worldnews | October 11, 2017 | 1 |
| 22509 | PROPAGANDA: Star Trek Beyond – Social Justice ... | Jay Dyer 21st Century WireThe last Star Trek r... | US_News | August 2, 2016 | 0 |
The gensim.utils.simple_process utility can be used to accomplish some of the basic common text preprocessing and cleaning such as tokenization and removing stop words.
stop_words = stopwords.words('english')
stop_words.extend(['said','say','from', 'subject', 're', 'edu', 'use'])
lemmatizer = WordNetLemmatizer()
stemmer = SnowballStemmer("english")
def preprocess(text):
result = []
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 2 and token not in stop_words:
#token = [stemmer.stem(token) for token in text.split() ]
result.append(lemmatizer.lemmatize(token))
return result
#@title Default title text
df["title"] = df["title"].apply(preprocess)
df["text"] = df["text"].apply(preprocess)
Combine title and text columns, this will later be used to demonstrate if classification performance improves with this combination over using either title or text column alone to predict whether the news is Fake or Real.
df["title_text"] = df["text"]+df["title"]
df.subject.value_counts()
politicsNews 11272
worldnews 10145
News 9050
politics 6841
left-news 4459
Government News 1570
US_News 783
Middle-east 778
Name: subject, dtype: int64
Looking at the subjects we can combine related subjects such politicsNews and politics to politicsNews.
df.subject.replace({'politics':'politicsNews'},inplace=True)
#df['label'] = df['label'].astype(str)
df["label"].replace({0:"Fake", 1:"Real"},inplace=True)
df["label"].value_counts()
Fake 23481
Real 21417
Name: label, dtype: int64
What is the distribution of Subjects between the True and Fake News?
temp=df.groupby('label').apply(lambda x:x['title'].count()).reset_index(name='Counts')
#temp.label.replace({0:'False',1:'True'},inplace=True)
temp.style.background_gradient(cmap='Purples')
| label | Counts | |
|---|---|---|
| 0 | Fake | 23481 |
| 1 | Real | 21417 |
#Let's draw a Funnel-Chart for better visualization
fig = go.Figure(go.Funnelarea(
text =temp.label,
values = temp.Counts,
title = {"position": "top center", "text": "Funnel-Chart of News Distribution"}
))
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file1.html")
temp=df.groupby('label').apply(lambda x:x['title'].count()).reset_index(name='Counts')
#sub_tf_df.label.replace({0:'False',1:'True'},inplace=True)
fig = px.bar(temp, x="label", y="Counts",
color='Counts', barmode='group',
title = "Frequency of Real and Fake News Distribution",
height=400)
fig.update_layout(
font_family="Courier New",
font_color="white",
title_font_family="Times New Roman",
title_font_color="white"
# legend_title_font_color="green"
)
fig.update_xaxes(title_font_family="Arial")
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="plotly_dark")
#fig =px.scatter(x=range(10), y=range(10))
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file2.html")
fig.show()
Common Words in News Fake News Title
top = Counter([item for sublist in df[df.label == "Fake"]["title"] for item in sublist])
temp = pd.DataFrame(top.most_common(20))
temp.columns = ['Common_words','count']
temp.style.background_gradient(cmap='Greens')
| Common_words | count | |
|---|---|---|
| 0 | trump | 9350 |
| 1 | video | 8558 |
| 2 | obama | 2582 |
| 3 | hillary | 2322 |
| 4 | watch | 1941 |
| 5 | clinton | 1175 |
| 6 | president | 1165 |
| 7 | black | 975 |
| 8 | tweet | 936 |
| 9 | white | 905 |
| 10 | new | 905 |
| 11 | breaking | 896 |
| 12 | news | 883 |
| 13 | republican | 867 |
| 14 | donald | 848 |
| 15 | muslim | 842 |
| 16 | gop | 807 |
| 17 | american | 772 |
| 18 | democrat | 772 |
| 19 | america | 703 |
fig = px.bar(temp, x="count", y="Common_words", title='Commmon Words in Fake News Titles', orientation='h',
width=700, height=700,color='Common_words')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="plotly_white")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file3.html")
Common Words in News Real News Title
top = Counter([item for sublist in df[df.label == "Real"]["title"] for item in sublist])
temp = pd.DataFrame(top.most_common(20))
temp.columns = ['Common_words','count']
temp.style.background_gradient(cmap='Purples')
| Common_words | count | |
|---|---|---|
| 0 | trump | 5567 |
| 1 | say | 2981 |
| 2 | house | 1452 |
| 3 | russia | 977 |
| 4 | republican | 976 |
| 5 | north | 926 |
| 6 | korea | 898 |
| 7 | new | 875 |
| 8 | state | 825 |
| 9 | white | 818 |
| 10 | china | 782 |
| 11 | senate | 759 |
| 12 | court | 753 |
| 13 | tax | 666 |
| 14 | obama | 665 |
| 15 | clinton | 659 |
| 16 | election | 656 |
| 17 | vote | 640 |
| 18 | talk | 597 |
| 19 | leader | 597 |
fig = px.bar(temp, x="count", y="Common_words", title='Commmon Words in Real news Titles', orientation='h',
width=700, height=700,color='Common_words')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="plotly_dark")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file4.html")
Which Subjects have received the most News Coverage?
temp=df.groupby('subject').apply(lambda x:x['title'].count()).reset_index(name='Counts')
fig=px.bar(temp,x='subject',y='Counts',color='Counts',title='Count of News Articles by Subject')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file2.html")
fig.update_layout( template="plotly_dark")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file5.html")
Exploring Co-occurring Words (Bigrams)
Let’s now explore certain words which occuur together in the tweets. Such words are called bigrams.A bigram or digram is a sequence of two adjacent elements from a string of tokens, which are typically letters, syllables, or words
from nltk import bigrams,trigrams,ngrams
# Create list of lists containing bigrams in tweets
terms_bigram = [list(bigrams(text)) for text in df[df.label == "Real"]["text"]]
# Flatten list of bigrams in clean tweets
bigrams_all = list(itertools.chain(*terms_bigram))
# Create counter of words in clean bigrams
bigram_counts = collections.Counter(bigrams_all)
bigram_df = pd.DataFrame(bigram_counts.most_common(20),
columns=['bigram', 'count'])
bigram_df.style.background_gradient(cmap='Purples')
| bigram | count | |
|---|---|---|
| 0 | ('united', 'state') | 12215 |
| 1 | ('donald', 'trump') | 10169 |
| 2 | ('white', 'house') | 8419 |
| 3 | ('washington', 'reuters') | 6674 |
| 4 | ('president', 'donald') | 5930 |
| 5 | ('north', 'korea') | 5659 |
| 6 | ('new', 'york') | 4740 |
| 7 | ('prime', 'minister') | 4206 |
| 8 | ('told', 'reuters') | 3496 |
| 9 | ('islamic', 'state') | 3477 |
| 10 | ('barack', 'obama') | 3344 |
| 11 | ('told', 'reporter') | 3189 |
| 12 | ('president', 'barack') | 2960 |
| 13 | ('hillary', 'clinton') | 2499 |
| 14 | ('supreme', 'court') | 2481 |
| 15 | ('trump', 'administration') | 2477 |
| 16 | ('reuters', 'president') | 2394 |
| 17 | ('year', 'old') | 2334 |
| 18 | ('united', 'nation') | 2322 |
| 19 | ('secretary', 'state') | 2317 |
#df = title_per.to_frame().round(1)
fig.update_layout(
title_text="High Frequency Bigrams in Real News",
# Add annotations in the center of the donut pies.
annotations=[dict(text='High Frequency ', x=0.5, y=0.5, font_size=14, showarrow=False)])
fig = px.pie(bigram_df, values=bigram_df['count'].values, names= bigram_df.bigram, color_discrete_sequence=px.colors.sequential.YlGnBu,
title='High Frquency Bigrams for Real News')
fig.update_traces(textposition='inside', textinfo='percent')
fig.update_layout(
# autosize=False,
width=800,
height=800,
)
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file6.html")
Bigrams of Fake News Headlines
# Create list of lists containing bigrams in tweets
terms_bigram = [list(bigrams(text)) for text in df[df.label == "Fake"]["text"]]
# Flatten list of bigrams in clean tweets
bigrams_all = list(itertools.chain(*terms_bigram))
# Create counter of words in clean bigrams
bigram_counts = collections.Counter(bigrams_all)
bigram_df = pd.DataFrame(bigram_counts.most_common(20),
columns=['bigram', 'count'])
bigram_df.style.background_gradient(cmap='Purples')
| bigram | count | |
|---|---|---|
| 0 | ('donald', 'trump') | 16402 |
| 1 | ('featured', 'image') | 8069 |
| 2 | ('hillary', 'clinton') | 7312 |
| 3 | ('white', 'house') | 6749 |
| 4 | ('united', 'state') | 6674 |
| 5 | ('twitter', 'com') | 6567 |
| 6 | ('pic', 'twitter') | 6232 |
| 7 | ('new', 'york') | 4361 |
| 8 | ('president', 'obama') | 4104 |
| 9 | ('president', 'trump') | 4065 |
| 10 | ('getty', 'image') | 4029 |
| 11 | ('fox', 'news') | 3524 |
| 12 | ('year', 'old') | 3248 |
| 13 | ('barack', 'obama') | 2352 |
| 14 | ('trump', 'supporter') | 2086 |
| 15 | ('century', 'wire') | 1930 |
| 16 | ('trump', 'campaign') | 1903 |
| 17 | ('supreme', 'court') | 1827 |
| 18 | ('fake', 'news') | 1818 |
| 19 | ('secretary', 'state') | 1764 |
colors = ['mediumturquoise','gold' ]
colors1 = ['#F4D03F','#82E0AA', "#F1948A",]
# Use `hole` to create a donut-like pie chart
fig = go.Figure(data=[go.Pie(labels= bigram_df.bigram, values=bigram_df['count'], hole=.4)])
fig.update_traces(hoverinfo='label+value', textinfo='percent', textfont_size=15,
marker=dict(colors=px.colors.sequential.YlGnBu, line=dict(color='#000000', width=1)))
fig.update_layout(
# autosize=False,
width=800,
height=800,
)
fig.update_layout(
title_text="High Frequency Bigrams in Fake News ",
# Add annotations in the center of the donut pies.
annotations=[dict(text=' ', x=0.5, y=0.5, font_size=14, showarrow=False)])
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file7.html")
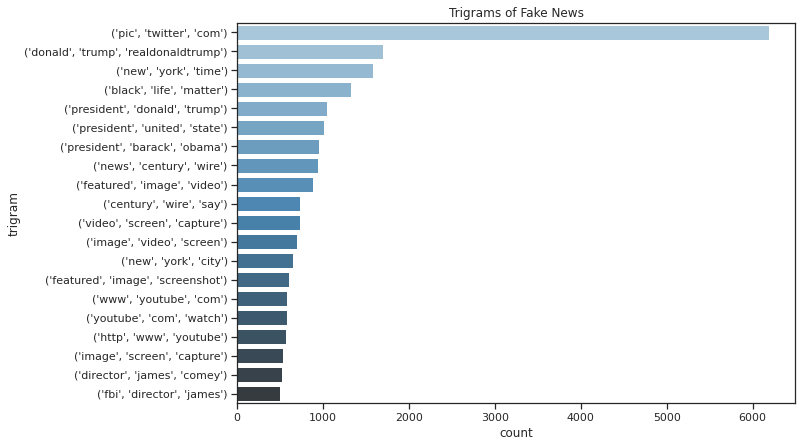
Trigrams of Fake News
#list(ngrams(df.text.values[0],n=4))
# Create list of lists containing bigrams in tweets
#trigram = [list(bigrams(tweet)) for tweet in df[df.label == "Fake"]["text"]]
trigram = [list(ngrams(text,n=3)) for text in df[df.label == "Fake"]["text"]]
# Flatten list of bigrams in clean tweets
trigram_all = list(itertools.chain(*trigram))
# Create counter of words in clean bigrams
trigram_counts = collections.Counter(trigram_all)
trigram_df = pd.DataFrame(trigram_counts.most_common(20),
columns=['trigram', 'count'])
trigram_df.style.background_gradient(cmap='Blues')
| trigram | count | |
|---|---|---|
| 0 | ('pic', 'twitter', 'com') | 6185 |
| 1 | ('donald', 'trump', 'realdonaldtrump') | 1692 |
| 2 | ('new', 'york', 'time') | 1581 |
| 3 | ('black', 'life', 'matter') | 1319 |
| 4 | ('president', 'donald', 'trump') | 1049 |
| 5 | ('president', 'united', 'state') | 1015 |
| 6 | ('president', 'barack', 'obama') | 953 |
| 7 | ('news', 'century', 'wire') | 939 |
| 8 | ('featured', 'image', 'video') | 887 |
| 9 | ('century', 'wire', 'say') | 733 |
| 10 | ('video', 'screen', 'capture') | 731 |
| 11 | ('image', 'video', 'screen') | 697 |
| 12 | ('new', 'york', 'city') | 651 |
| 13 | ('featured', 'image', 'screenshot') | 607 |
| 14 | ('www', 'youtube', 'com') | 577 |
| 15 | ('youtube', 'com', 'watch') | 575 |
| 16 | ('http', 'www', 'youtube') | 571 |
| 17 | ('image', 'screen', 'capture') | 529 |
| 18 | ('director', 'james', 'comey') | 518 |
| 19 | ('fbi', 'director', 'james') | 500 |
#fig = px.bar(trigram_df, x="count", y="trigram", title='Trigrams in Fake News', orientation='h',
# width=700, height=700)
#fig.show()
# plot
sns.set_style('ticks')
fig, ax = plt.subplots()
# the size of A4 paper
fig.set_size_inches(10, 7)
ax = sns.barplot(x="count", y="trigram", data=trigram_df,
palette="Blues_d")
plt.title('Trigrams of Fake News')
plt.show()
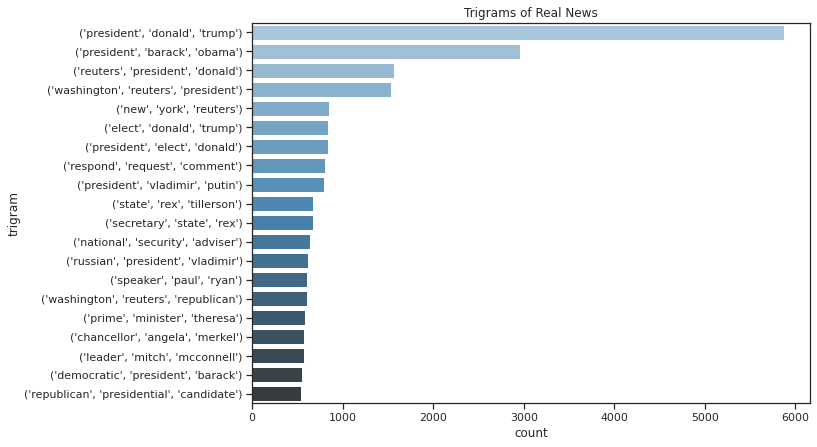
Trigrams of Real News
trigram = [list(ngrams(text,n=3)) for text in df[df.label == "Real"]["text"]]
# Flatten list of bigrams in clean tweets
trigram_all = list(itertools.chain(*trigram))
# Create counter of words in clean bigrams
trigram_counts = collections.Counter(trigram_all)
trigram_df = pd.DataFrame(trigram_counts.most_common(20),
columns=['trigram', 'count'])
trigram_df.style.background_gradient(cmap='Blues')
| trigram | count | |
|---|---|---|
| 0 | ('president', 'donald', 'trump') | 5869 |
| 1 | ('president', 'barack', 'obama') | 2960 |
| 2 | ('reuters', 'president', 'donald') | 1562 |
| 3 | ('washington', 'reuters', 'president') | 1533 |
| 4 | ('new', 'york', 'reuters') | 845 |
| 5 | ('elect', 'donald', 'trump') | 834 |
| 6 | ('president', 'elect', 'donald') | 832 |
| 7 | ('respond', 'request', 'comment') | 806 |
| 8 | ('president', 'vladimir', 'putin') | 791 |
| 9 | ('state', 'rex', 'tillerson') | 673 |
| 10 | ('secretary', 'state', 'rex') | 672 |
| 11 | ('national', 'security', 'adviser') | 639 |
| 12 | ('russian', 'president', 'vladimir') | 613 |
| 13 | ('speaker', 'paul', 'ryan') | 608 |
| 14 | ('washington', 'reuters', 'republican') | 603 |
| 15 | ('prime', 'minister', 'theresa') | 584 |
| 16 | ('chancellor', 'angela', 'merkel') | 570 |
| 17 | ('leader', 'mitch', 'mcconnell') | 568 |
| 18 | ('democratic', 'president', 'barack') | 550 |
| 19 | ('republican', 'presidential', 'candidate') | 541 |
sns.set_style('ticks')
fig, ax = plt.subplots()
# the size of A4 paper
fig.set_size_inches(10, 7)
ax = sns.barplot(x="count", y="trigram", data=trigram_df,
palette="Blues_d")
plt.title('Trigrams of Real News')
plt.show()
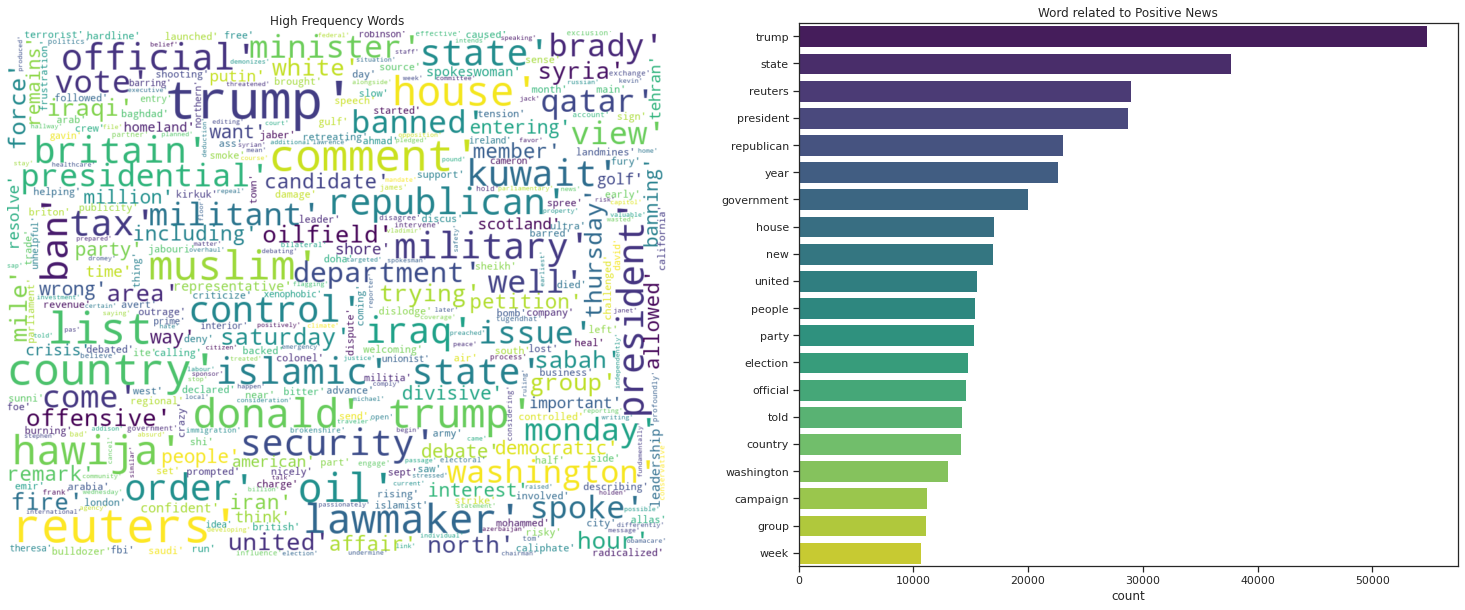
Word Cloud using the Real News
top = Counter([item for sublist in df[df.label == "Real"]["text"] for item in sublist])
temp = pd.DataFrame(top.most_common(20))
temp.columns = ['Common_words','count']
temp.style.background_gradient(cmap='Blues')
| Common_words | count | |
|---|---|---|
| 0 | trump | 54734 |
| 1 | state | 37678 |
| 2 | reuters | 28976 |
| 3 | president | 28728 |
| 4 | republican | 23007 |
| 5 | year | 22622 |
| 6 | government | 19992 |
| 7 | house | 17030 |
| 8 | new | 16917 |
| 9 | united | 15590 |
| 10 | people | 15356 |
| 11 | party | 15294 |
| 12 | election | 14759 |
| 13 | official | 14620 |
| 14 | told | 14245 |
| 15 | country | 14161 |
| 16 | washington | 12988 |
| 17 | campaign | 11155 |
| 18 | group | 11129 |
| 19 | week | 10658 |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.model_selection import train_test_split # function for splitting data to train and test sets
import nltk
from nltk.corpus import stopwords
from nltk.classify import SklearnClassifier
from wordcloud import WordCloud,STOPWORDS
import matplotlib.pyplot as plt
%matplotlib inline
from subprocess import check_output
from os import path
from wordcloud import WordCloud
#d = path.dirname("/Users/nanaakwasiabayieboateng/PythonNLTK")
# Read the whole text.
#text = str(train['text'])
#stopwords = set(STOPWORDS)
#stopwords.add("Chrysler")
color = ['black','white'];
#background_color="white", max_words=2000, mask=text,
# stopwords=stopwords, contour_width=3, contour_color='steelblue'
fig, (ax1, ax2,) = plt.subplots(1, 2, figsize=[26, 10])
sns.set_color_codes("pastel")
wordcloud = WordCloud(max_words = 2000,
width=1000,
height=800,
colormap='viridis',
max_font_size=80, min_font_size=2, # Font size range
background_color=color[1],
margin=0,
stopwords = stop_words).generate("".join(str(df[df.label == "Real"].text.values)))
ax1.imshow(wordcloud, interpolation = 'bilinear')
sns.color_palette("viridis", as_cmap=True)
ax2= sns.barplot(y="Common_words", x="count", data=temp,
label="Total",palette="viridis")
ax2.set_ylabel('')
ax2.set_title('Word related to Positive News');
#ax1.imshow(wordcloud)
ax1.axis('off')
ax1.set_title('High Frequency Words');
Word Cloud using the Real News
Lets Look at the Count of Words Distribution in the Title
top = Counter([item for sublist in df[df.label == "Fake"]["text"] for item in sublist])
temp = pd.DataFrame(top.most_common(20))
temp.columns = ['Common_words','count']
temp.style.background_gradient(cmap='Greens')
| Common_words | count | |
|---|---|---|
| 0 | trump | 80049 |
| 1 | president | 28406 |
| 2 | people | 26678 |
| 3 | state | 23663 |
| 4 | clinton | 19866 |
| 5 | time | 19199 |
| 6 | year | 19074 |
| 7 | obama | 18838 |
| 8 | like | 18667 |
| 9 | american | 18106 |
| 10 | donald | 17780 |
| 11 | republican | 16756 |
| 12 | right | 14857 |
| 13 | news | 14679 |
| 14 | new | 14416 |
| 15 | image | 14312 |
| 16 | hillary | 14192 |
| 17 | white | 13573 |
| 18 | know | 12062 |
| 19 | medium | 11847 |
fig, (ax1, ax2,) = plt.subplots(1, 2, figsize=[26, 10])
sns.set_color_codes("pastel")
color = ['black','white'];
wordcloud = WordCloud(max_words = 2000,
width=1000,
height=800,
colormap='viridis',
max_font_size=80, min_font_size=2, # Font size range
background_color=color[1],
margin=0,
stopwords = stop_words).generate("".join(str(df[df.label == "Fake"].text.values)))
ax1.imshow(wordcloud, interpolation = 'bilinear')
sns.color_palette("viridis", as_cmap=True)
ax2= sns.barplot(y="Common_words", x="count", data=temp,
label="Total",palette="viridis")
ax2.set_ylabel('')
ax2.set_title('Word related to Positive News');
#ax1.imshow(wordcloud)
ax1.axis('off')
ax1.set_title('High Frequency Words');
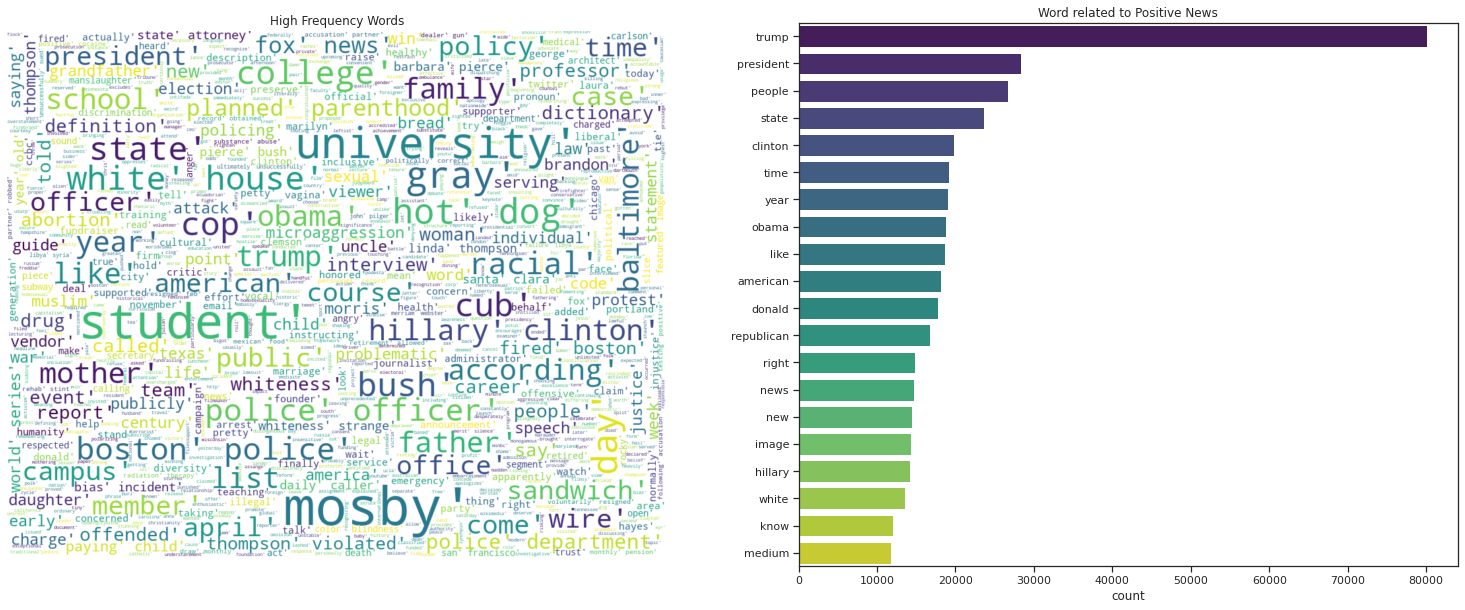
Donald Trunmp dominates the news whether fake or real.
Analysis Over Time
import datetime
from IPython.display import display, HTML
df["date"] = pd.to_datetime(df["date"], errors='coerce')
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
h= df.head(2)
# render dataframe as html
html = h.to_html(render_links=True, index=False).replace('<th>','<th style = "background-color: #48c980">')
# write html to file
text_file = open("/content/drive/MyDrive/Colab Notebooks/NLP/h.html", "w")
text_file.write(html)
text_file.close()
HTML('h.html')
import seaborn as sns
temp=df.groupby('year').apply(lambda x:x['text'].count()).reset_index(name='Counts')
temp.style.set_properties(**{'background-color': 'pink',
'color': 'black',
'border-color': 'white'})
temp.style.background_gradient(cmap='Greens')
| year | Counts | |
|---|---|---|
| 0 | 2015.000000 | 2479 |
| 1 | 2016.000000 | 16470 |
| 2 | 2017.000000 | 25904 |
| 3 | 2018.000000 | 35 |
temp=df.groupby('year').apply(lambda x:x['text'].count()).reset_index(name='Counts')
#temp['year'] = temp['year'].astype(str)
fig = px.bar(temp, x="year", y="Counts",color="Counts",text='Counts')
#fig = px.histogram(temp, x="year", y="Counts")
fig.update_layout(
title=" Frequency of Words Used In News per Year",
xaxis_title="Year",
yaxis_title="Frequency",
#legend_title="",
font=dict(
family="Courier New, monospace",
size=18,
color="RebeccaPurple"
)
)
#Forcing an axis to be categorical
fig.update_xaxes(type='category')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="plotly_white")
#fig.update_yaxes(title='')
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file8.html")
temp=df.groupby('month').apply(lambda x:x['text'].count()).reset_index(name='Counts')
temp.style.clear()
cm = sns.light_palette("green", as_cmap=True)
temp.style.background_gradient(cmap=cm)
| month | Counts | |
|---|---|---|
| 0 | 1.000000 | 3106 |
| 1 | 2.000000 | 2957 |
| 2 | 3.000000 | 3336 |
| 3 | 4.000000 | 3034 |
| 4 | 5.000000 | 3076 |
| 5 | 6.000000 | 2896 |
| 6 | 7.000000 | 2829 |
| 7 | 8.000000 | 2829 |
| 8 | 9.000000 | 5199 |
| 9 | 10.000000 | 5476 |
| 10 | 11.000000 | 5536 |
| 11 | 12.000000 | 4614 |
temp=df.groupby('month').apply(lambda x:x['text'].count()).reset_index(name='Counts')
temp.style.background_gradient(cmap=cm)
#fig = px.scatter(temp, x="day", y="Counts",mode='lines+markers')
fig = go.Figure()
#fig.add_trace(go.bar(x=temp.day, y=temp.Counts ))
#fig = px.line(temp, x="day", y="Counts")
fig = px.bar(temp, x="month", y="Counts",color="Counts")
fig.update_layout(
title=" Frequency of Words Used In News per Month of the Year",
xaxis_title="Month",
yaxis_title="Frequency",
#legend_title="",
font=dict(
family="Courier New, monospace",
size=18,
color="white"
)
)
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="plotly_dark")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file9.html")
temp=df.groupby('day').apply(lambda x:x['text'].count()).reset_index(name='Counts')
#fig = px.scatter(temp, x="day", y="Counts",mode='lines+markers')
fig = go.Figure()
fig.add_trace(go.Scatter(x=temp.day, y=temp.Counts,
marker=dict(
color=np.random.randn(temp.shape[0]),
colorscale='Viridis',
line_width=1
),
mode='lines+markers'))
#fig = px.line(temp, x="day", y="Counts")
fig.update_layout(
title=" Frequency of Words Used In News per Day of the Month",
xaxis_title="Month",
yaxis_title="Frequency",
#legend_title="",
font=dict(
family="Courier New, monospace",
size=18,
color="RebeccaPurple"
)
)
fig.update_xaxes(tickvals=temp.day,tickangle=45)
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout( template="seaborn")
#fig.update_xaxes(showticklabels=False)
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file10.html")
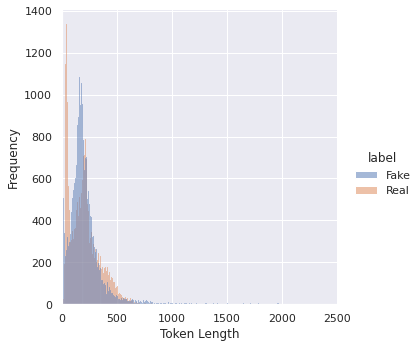
Distribution of Token Lengths
df["token_length"] = df["text"].apply(lambda x : len(x))
df.head()
| title | text | subject | date | label | title_text | year | month | day | token_length | |
|---|---|---|---|---|---|---|---|---|---|---|
| 3056 | [chicago, cub, snub, trump, visit, white, hous... | [unprecedented, clear, aimed, donald, trump, n... | News | 2017-01-11 | Fake | [unprecedented, clear, aimed, donald, trump, n... | 2017.0 | 1.0 | 11.0 | 152 |
| 21285 | [outrageous, example, radical, allowed, colleg... | [war, expect, child, fight, war, leftist, acad... | left-news | 2015-11-28 | Fake | [war, expect, child, fight, war, leftist, acad... | 2015.0 | 11.0 | 28.0 | 570 |
| 11575 | [wow, barbara, bush, keynote, speaker, baby, k... | [father, staunch, supporter, life, mother, voc... | politicsNews | 2017-02-25 | Fake | [father, staunch, supporter, life, mother, voc... | 2017.0 | 2.0 | 25.0 | 149 |
| 267 | [trump, puerto, rico, disgustingly, tell, puer... | [thought, possibly, worse, donald, trump, lowe... | News | 2017-10-03 | Fake | [thought, possibly, worse, donald, trump, lowe... | 2017.0 | 10.0 | 3.0 | 115 |
| 18532 | [islamic, state, torch, oil, well, northern, i... | [baghdad, reuters, islamic, state, militant, s... | worldnews | 2017-10-02 | Real | [baghdad, reuters, islamic, state, militant, s... | 2017.0 | 10.0 | 2.0 | 120 |
import plotly.figure_factory as ff
import numpy as np
# Group data together
hist_data = [df[df.label=="Fake"]["token_length"], df[df.label=="Real"]["token_length"]]
group_labels = ['Fake', 'Real']
colors = ['slategray', 'magenta']
# Create distplot with custom bin_size
fig = ff.create_distplot(hist_data, group_labels, bin_size=.2,
curve_type='normal', # override default 'kde'
colors=colors)
#fig = ff.create_distplot(hist_data, group_labels, show_hist=False, colors=colors)
# Add title
#fig.update_layout(title_text='Distribution of Text Token Counts')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout(xaxis_range=[0,1500])
fig.update_layout( template="plotly")
fig.update_layout(
autosize=False,
width=1000,
height=600,)
fig.update_layout(
title=" Distribution of Text Token Counts",
xaxis_title="Token Length",
yaxis_title="Frequency")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file11.html")
Most token lengths for the news items is between 0 to 500 words.
from matplotlib import pyplot as plt
import seaborn as sns
from matplotlib import rcParams
# figure size in inches
#rcParams['figure.figsize'] = 11.7,8.27
#plt.figure(figsize=(12,10))
#multiple="stack",, kind="kde", fill=True
sns.set_theme();
sns.set(rc={'figure.figsize':(13,10)})
#fig, ax = plt.subplots()
#sns.set_size_inches(11.7, 8.27)
sns.displot(df, x="token_length",hue="label")
plt.xlim([0, 2500]);
plt.xlabel('Token Length');
plt.ylabel('Frequency');
plt.show()
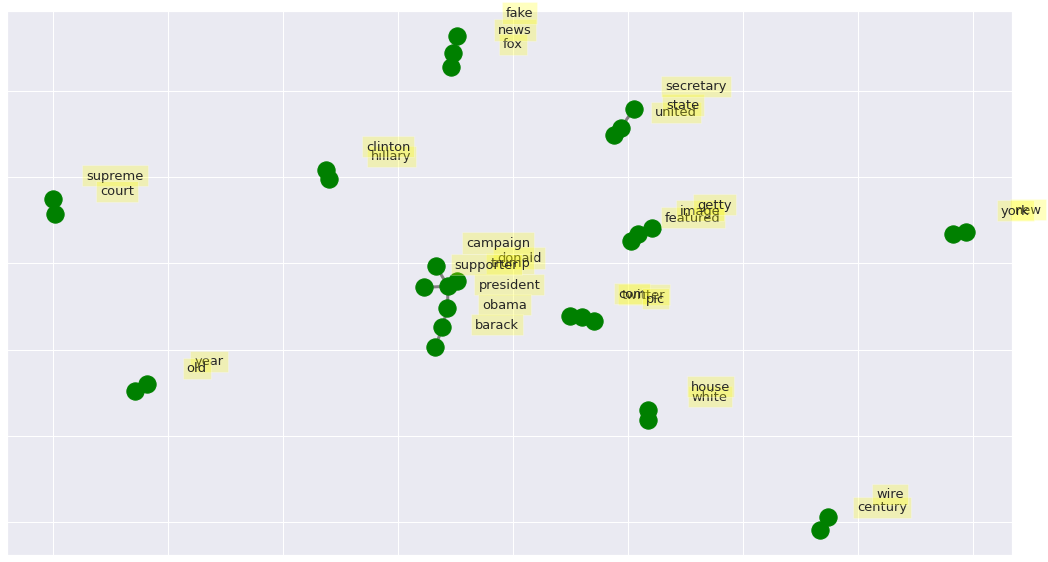
Visualizing Networks of Co-occurring Word
The bigrams can be visualized looking at the top occurring bigrams as networks using the Python package NetworkX.
import networkx as nx
# Create dictionary of bigrams and their counts
d = bigram_df.set_index('bigram').T.to_dict('records')
# Create network plot
G = nx.Graph()
# Create connections between nodes
for k, v in d[0].items():
G.add_edge(k[0], k[1], weight=(v * 5))
fig, ax = plt.subplots(figsize=(18, 10))
pos = nx.spring_layout(G, k=2)
# Plot networks
nx.draw_networkx(G, pos,
font_size=16,
width=3,
edge_color='grey',
node_color='green',
with_labels = False,
ax=ax)
# Create offset labels
for key, value in pos.items():
x, y = value[0]+.135, value[1]+.045
ax.text(x, y,
s=key,
bbox=dict(facecolor='yellow', alpha=0.25),
horizontalalignment='center', fontsize=13)
plt.show()
Sentiment Analysis with Vader
- For top 2000 highest frequency words in Fake/Real determine polarity of each with vader from Textblob package. The polarity will then be used to classify news as either negative,positive or neutral.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.sentiment.util import *
from textblob import TextBlob
from nltk import tokenize
#df.info()
df.drop_duplicates(subset = "text", keep = "first", inplace = True)
def get_polarity(text):
return TextBlob(text).sentiment.polarity
df['Polarity'] = df['text'].progress_apply(get_polarity)
HBox(children=(FloatProgress(value=0.0, max=38646.0), HTML(value='')))
df['sentiment_vader']=''
df.loc[df.Polarity>0,'sentiment_vader']='POSITIVE'
df.loc[df.Polarity==0,'sentiment_vader']='NEUTRAL'
df.loc[df.Polarity<0,'sentiment_vader']='NEGATIVE'
#df.head()
df["label"].replace({0:"Fake", 1:"Real"},inplace=True)
temp=df.groupby(['label','sentiment_vader']).apply(lambda x:x['sentiment_vader'].count()).reset_index(name='Counts')
temp.style.background_gradient(cmap='Greens')
| label | sentiment_vader | Counts | |
|---|---|---|---|
| 0 | Fake | NEGATIVE | 4185 |
| 1 | Fake | NEUTRAL | 322 |
| 2 | Fake | POSITIVE | 12947 |
| 3 | Real | NEGATIVE | 4654 |
| 4 | Real | NEUTRAL | 551 |
| 5 | Real | POSITIVE | 15987 |
#temp=df.groupby(['label','sentiment_vader']).agg(['count']).reset_index()[['label','sentiment_vader','title']]
#temp.rename(columns={'title': 'Counts'}, inplace=True)
#temp
#
fig = px.bar(temp, x="label", y="Counts", facet_col="sentiment_vader",
color=["crimson","crimson","crimson","green","green","green"],text='Counts')
#Forcing an axis to be categorical
fig.update_xaxes(type='category')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout(showlegend=False)
fig.update_layout( template="plotly_white")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file12.html")
fig = px.bar(temp, x="label", y="Counts",color="sentiment_vader", barmode="group",text='Counts')
#Forcing an axis to be categorical
fig.update_xaxes(type='category')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout(title_text='Sentiment Distribution over Real and Fake News')
fig.update_traces(texttemplate='%{text:.2s}', textposition='outside')
fig.update_layout(barmode='group', xaxis_tickangle=0)
fig.update_layout(barmode='group', xaxis={'categoryorder':'category ascending'})
fig.update_layout(
legend=dict(
x=1,
y=1,
traceorder="reversed",
#title_font_family="Times New Roman",
font=dict(
family="Courier",
size=12,
color="black"
),
bgcolor="LightSteelBlue",
bordercolor="Black",
borderwidth=2
)
)
fig.update_layout( template="simple_white")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file13.html")
Has the News Grown More Negative Between 2015 to 2018?
Yes. The proportion of negative sentiments in the news has increased between 2015 to 2017.
df.head()
| title | text | subject | date | label | Polarity | sentiment_vader | year | month | day | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | As U.S. budget fight looms, Republicans flip t... | WASHINGTON (Reuters) - The head of a conservat... | politicsNews | 2017-12-31 | Real | 0.037083 | POSITIVE | 2017.0 | 12.0 | 31.0 |
| 1 | U.S. military to accept transgender recruits o... | WASHINGTON (Reuters) - Transgender people will... | politicsNews | 2017-12-29 | Real | 0.055880 | POSITIVE | 2017.0 | 12.0 | 29.0 |
| 2 | Senior U.S. Republican senator: 'Let Mr. Muell... | WASHINGTON (Reuters) - The special counsel inv... | politicsNews | 2017-12-31 | Real | 0.115930 | POSITIVE | 2017.0 | 12.0 | 31.0 |
| 3 | FBI Russia probe helped by Australian diplomat... | WASHINGTON (Reuters) - Trump campaign adviser ... | politicsNews | 2017-12-30 | Real | 0.035968 | POSITIVE | 2017.0 | 12.0 | 30.0 |
| 4 | Trump wants Postal Service to charge 'much mor... | SEATTLE/WASHINGTON (Reuters) - President Donal... | politicsNews | 2017-12-29 | Real | 0.030093 | POSITIVE | 2017.0 | 12.0 | 29.0 |
df["date"] = pd.to_datetime(df["date"], errors='coerce')
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['year'] = df['year'].fillna(0)
df['year'] = df['year'].astype(int)
temp=df.groupby(['year','sentiment_vader']).agg({'title':'count'}).query('year>0')
temp = temp.groupby(level=0).apply(lambda x:1 * x / float(x.sum())).reset_index()
temp.rename(columns={'title': 'Ratio'}, inplace=True)
temp.style.background_gradient(cmap='Blues')
| year | sentiment_vader | Ratio | |
|---|---|---|---|
| 0 | 2015 | NEGATIVE | 0.250470 |
| 1 | 2015 | NEUTRAL | 0.028804 |
| 2 | 2015 | POSITIVE | 0.720726 |
| 3 | 2016 | NEGATIVE | 0.199669 |
| 4 | 2016 | NEUTRAL | 0.021059 |
| 5 | 2016 | POSITIVE | 0.779271 |
| 6 | 2017 | NEGATIVE | 0.244642 |
| 7 | 2017 | NEUTRAL | 0.022905 |
| 8 | 2017 | POSITIVE | 0.732453 |
| 9 | 2018 | NEGATIVE | 0.314286 |
| 10 | 2018 | POSITIVE | 0.685714 |
fig = px.bar(temp, x="year", y="Ratio",color="sentiment_vader", barmode="group")
#Forcing an axis to be categorical
fig.update_xaxes(type='category')
#fig.update_traces(texttemplate='%{text:.2s}', textposition='outside')
fig.update_xaxes(type='category')
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout(title_text='Sentiment Distribution over Real and Fake News')
#fig.update_traces( texttemplate='{}',textposition='outside')
fig.update_layout(barmode='group', xaxis_tickangle=-45)
fig.update_layout(barmode='group', xaxis={'categoryorder':'category ascending'})
fig.update_layout(yaxis=dict(tickformat=".0%"))
fig.update_yaxes(title="Percent",title_font_family="Arial")
fig.update_layout( template="ggplot2")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file14.html")
temp=df.groupby(['day','sentiment_vader']).agg({'title':'count'})
temp = temp.groupby(level=0).apply(lambda x:1 * x / float(x.sum())).reset_index()
temp.rename(columns={'title': 'Ratio'}, inplace=True)
#fig = px.line(temp, x="day", y="Ratio",color="sentiment_vader",line_group="sentiment_vader")
fig = go.Figure()
fig.add_trace(go.Scatter(x=temp[temp.sentiment_vader=="POSITIVE"]["day"],
y=temp[temp.sentiment_vader=="POSITIVE"]["Ratio"],
mode='lines+markers',
name='POSITIVE'))
fig.add_trace(go.Scatter(x=temp[temp.sentiment_vader=="NEGATIVE"]["day"],
y=temp[temp.sentiment_vader=="NEGATIVE"]["Ratio"],
mode='lines+markers',
name='NEGATIVE'))
fig.add_trace(go.Scatter(x=temp[temp.sentiment_vader=="NEUTRAL"]["day"],
y=temp[temp.sentiment_vader=="NEUTRAL"]["Ratio"],
mode='lines+markers', name='NEUTRAL'))
fig.update_xaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_yaxes(showline=True, linewidth=2, linecolor='black', mirror=True)
fig.update_layout(title_text='Sentiment Distribution over Real and Fake News Every Day of The Month')
fig.update_layout( template="plotly_dark")
fig.update_layout(xaxis_tickangle=-45)
#["plotly", "plotly_white", "plotly_dark", "ggplot2", "seaborn", "simple_white", "none"]
fig.update_layout(yaxis=dict(tickformat=".0%"))
fig.update_yaxes(title="Percent",title_font_family="Arial")
fig.show()
fig.write_html("/content/drive/MyDrive/Colab Notebooks/NLP/htmlfies/file15.html")
Classification of News as Real or Fake using Titles as Features
%%time
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
y= le.fit_transform(df.label)
X_train, X_test, y_train, y_test = train_test_split(df.title, y, test_size = 0.2,random_state=2)
#vectorizer = CountVectorizer().fit(X_train)
vectorizer = TfidfVectorizer(use_idf=True).fit(X_train)
train_x = vectorizer.transform(X_train)
test_x = vectorizer.transform(X_test)
model = LogisticRegression(C=2.5)
model.fit(train_x, y_train)
y_pred = model.predict(test_x)
accuracy_value = roc_auc_score(y_test, y_pred)
print("accuracy score {}".format(accuracy_value))
accuracy score 0.9568209165268219
CPU times: user 1.77 s, sys: 1.14 s, total: 2.91 s
Wall time: 2.31 s
The title alone can predict fake or reals by nearly 96% accuracy.
Classification of News as Real or Fake with Text as Features
%%time
X_train, X_test, y_train, y_test = train_test_split(df.text, y, test_size = 0.2,random_state=2)
vectorizer = CountVectorizer().fit(X_train)
#vectorizer = TfidfVectorizer(use_idf=True).fit(X_train)
train_x = vectorizer.transform(X_train)
test_x = vectorizer.transform(X_test)
model = xgb.XGBClassifier(
n_jobs = -1,
max_depth = 6,
#learning_rate= 0.1,
min_child_weight= 2,
#min_samples_split= 0.9,
n_estimators= 100,
eta = 0.1,
verbose = 1,
gamma=0.05,
#nrounds = 100
objective = "binary:logistic",
eval_metric = "auc", #"aucpr", # "aucpr", #aucpr, auc
subsample = 0.7,
colsample_bytree =0.8,
max_delta_step=1,
verbosity=1,
tree_method='approx')
model.fit(train_x, y_train)
y_pred = model.predict(test_x)
accuracy_value = roc_auc_score(y_test, y_pred)
print("accuracy score {}".format(accuracy_value))
accuracy score 0.9970340274765952
CPU times: user 3min 45s, sys: 359 ms, total: 3min 45s
Wall time: 2min 8s
Classification of News as Real or Fake with Title and Text Combined as Features
%%time
X_train, X_test, y_train, y_test = train_test_split(df.title_text, y, test_size = 0.2,random_state=2)
vectorizer = CountVectorizer().fit(X_train)
#vectorizer = TfidfVectorizer(use_idf=True).fit(X_train)
train_x = vectorizer.transform(X_train)
test_x = vectorizer.transform(X_test)
model = xgb.XGBClassifier(
n_jobs = -1,
max_depth = 6,
#learning_rate= 0.1,
min_child_weight= 2,
#min_samples_split= 0.9,
n_estimators= 100,
eta = 0.1,
verbose = 1,
gamma=0.05,
#nrounds = 100
objective = "binary:logistic",
eval_metric = "auc", #"aucpr", # "aucpr", #aucpr, auc
subsample = 0.7,
colsample_bytree =0.8,
max_delta_step=1,
verbosity=1,
tree_method='approx')
#model = LogisticRegression(C=2.5)
model.fit(train_x, y_train)
y_pred = model.predict(test_x)
accuracy_value = roc_auc_score(y_test, y_pred)
print("accuracy score {}".format(accuracy_value))
accuracy score 0.9975657161197259
CPU times: user 3min 51s, sys: 693 ms, total: 3min 52s
Wall time: 2min 12s
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import seaborn as sns
p=0.5
def PlotConfusionMatrix(y_test,pred,y_test_normal,y_test_pneumonia,label):
cfn_matrix = confusion_matrix(y_test,pred)
cfn_norm_matrix = np.array([[1.0 / y_test_normal,1.0/y_test_normal],[1.0/y_test_pneumonia,1.0/y_test_pneumonia]])
norm_cfn_matrix = cfn_matrix * cfn_norm_matrix
#colsum=cfn_matrix.sum(axis=0)
#norm_cfn_matrix = cfn_matrix / np.vstack((colsum, colsum)).T
fig = plt.figure(figsize=(15,5))
ax = fig.add_subplot(1,2,1)
#sns.heatmap(cfn_matrix,cmap='magma',linewidths=0.5,annot=True,ax=ax,annot=True)
sns.heatmap(cfn_matrix, annot = True,fmt='g',cmap='rocket')
#tick_marks = np.arange(len(y_test))
#plt.xticks(tick_marks, np.unique(y_test), rotation=45)
plt.title('Confusion Matrix',color='b')
plt.ylabel('Real Classes')
plt.xlabel('Predicted Classes')
plt.savefig('/content/drive/My Drive/Colab Notebooks/NLP/cm_' +label + '.png')
ax = fig.add_subplot(1,2,2)
sns.heatmap(norm_cfn_matrix,cmap=plt.cm.Blues,linewidths=0.5,ax=ax,annot=True)
plt.title('Normalized Confusion Matrix',color='b')
plt.ylabel('Real Classes')
plt.xlabel('Predicted Classes')
plt.savefig('/content/drive/My Drive/Colab Notebooks/NLP/cm_norm' +label + '.png')
plt.show()
print('---Classification Report---')
print(classification_report(y_test,pred))
y_test_real,y_test_fake = np.bincount(y_test)
y_pred= np.where(y_pred<p,0,1 )
PlotConfusionMatrix(y_test,y_pred,y_test_real,y_test_fake,label= 'classification Report')
---Classification Report---
precision recall f1-score support
0 1.00 1.00 1.00 4702
1 1.00 1.00 1.00 4278
accuracy 1.00 8980
macro avg 1.00 1.00 1.00 8980
weighted avg 1.00 1.00 1.00 8980