Overview
Large language models (LLMs) have revolutionized natural language processing by enabling advanced applications such as text generation, sentiment analysis, and conversational agents. Running these models on a local machine allows developers and enthusiasts to leverage their power without relying on cloud services, promoting greater accessibility and experimentation. However, successfully implementing LLMs locally necessitates a thorough understanding of the associated hardware and software requirements, as well as optimal setup procedures. To effectively utilize LLMs on a personal computer, users must meet specific hardware specifications, including system compatibility, adequate memory, and powerful GPUs capable of handling extensive computational tasks. For instance, models with billions of parameters demand substantial RAM and GPU resources, making it essential for users to evaluate their system capabilities before installation. Additionally, software frameworks like TensorFlow and PyTorch are integral to managing LLMs, necessitating a well-configured environment to ensure seamless operation. Setting up a local environment involves several critical steps, including creating virtual environments, installing necessary libraries, and managing dependencies. Users must also navigate potential challenges such as installation errors and performance optimization, particularly regarding memory management and GPU acceleration. Addressing these concerns is crucial for maximizing the performance and responsiveness of LLMs on personal machines, allowing users to tailor models to specific tasks effectively. While local implementation of LLMs is increasingly accessible, it is not without its complexities. Notable challenges include hardware limitations, compatibility issues, and the need for efficient troubleshooting strategies. Understanding these intricacies is vital for users aiming to harness the full potential of LLMs, ensuring they can execute advanced AI applications locally while mitigating common pitfalls associated with setup and performance optimization.
Requirements
To effectively run large language models (LLMs) on a local machine, it is crucial to understand and meet specific hardware and software requirements. This ensures optimal performance and a smooth user experience while leveraging the capabilities of LLMs.
Hardware Requirements
System Compatibility
Before diving into the installation of an LLM, you need to ensure that your operating system is compatible. For MacOS users, versions 11 Big Sur or later are recommended, while Linux users should have Ubuntu 18.04 or later. Windows users can utilize Windows Subsystem for Linux 2 (WSL2) to run LLMs effectively on their machines[1].
Memory Specifications
Memory plays a vital role in running LLMs. For smaller models, such as those with around 3 billion parameters, a minimum of 8GB of RAM is necessary. As the model size increases, so do the memory requirements; 7B models require 16GB of RAM, while 13B models benefit from at least 32GB[1][2]. Ensuring adequate memory is essential for smooth operation and responsiveness of the models.
GPU Requirements
The GPU is arguably the most critical component when it comes to running LLMs. They are responsible for handling the complex matrix multiplications and parallel processing tasks required for both training and inference. Recommended GPUs for LLM tasks include the NVIDIA A100 Tensor Core GPU, which has 40GB or more of VRAM, and consumer-grade options like the NVIDIA RTX 4090/3090, which feature 24GB of VRAM [2][3]. Additionally, for larger models, having a GPU with at least 10GB of VRAM is advisable to ensure efficient processing[4].
Disk Space and Storage
Adequate disk space is essential for installing the necessary software and storing model files. While the specific requirements can vary based on the models being used, ensuring you have sufficient space to accommodate multiple models and datasets is vital.
Software Requirements
Operating System and Software Support It is important to have a system that supports the necessary software frameworks and libraries for LLMs, such as TensorFlow, PyTorch, Hugging Face Transformers, and DeepSpeed. Most AI developers prefer Linux-based systems due to better support for these tools[2][3].
Networking and Connectivity
For larger deployments or setups involving multiple machines, a robust networking setup is essential. A 10 Gigabit Ethernet connection is recommended for transferring large model checkpoints or datasets efficiently. If relying on wireless connectivity, WiFi 6 is advisable for improved throughput and reduced latency[2][3].
Setting Up the Environment
To successfully utilize large language models (LLMs) on a local machine, it’s crucial to set up your development environment correctly. This process involves creating virtual environments, installing necessary dependencies, and ensuring that your system meets specific requirements.
Downloading Large Language Models
Downloading large language models (LLMs) for local use is a crucial step for individuals and developers aiming to leverage these powerful tools for various applications. This section outlines the key considerations and steps involved in obtaining LLMs.
Accessing Model Repositories
The primary source for downloading LLMs is online repositories, with Hugging Face being one of the most popular platforms. Users can search for models based on their specific needs and select from a wide range of options, including models tuned for conversational tasks, such as instruct-tuned variants designed to handle interactive dialogues effectively[5][6].
Choosing the Right Model
When selecting a model, it is essential to consider its architecture and intended use case. Many models come pre-trained and can be fine-tuned for specific tasks or applications. For example, models like GPT-3 and BERT are widely recognized for their versatility in natural language processing tasks, ranging from text generation to sentiment analysis[7]. Additionally, it’s important to pay attention to model specifications, such as the number of parameters and quantization options, which can affect performance and resource requirements[8][5].
Downloading and Managing Models
Once a suitable model is identified, downloading it is typically straightforward. Many LLM frameworks provide built-in mechanisms to handle model downloads seamlessly, often defaulting to versions optimized for local usage, such as 4-bit quantized models[6]. For a manual approach, users can directly visit the Hugging Face Model Hub, where they can select the desired model repository and download the model files. The process generally involves copying the model name and specific file needed for implementation[5].
Setting Up the Environment
After downloading, users will need to set up their local environment to run the model. This often includes installing required libraries and dependencies specific to the framework being used, such as TensorFlow or PyTorch. Users should familiarize themselves with the framework’s documentation to ensure proper configuration and optimization for their hardware setup[7][9].
Running Large Language Models Locally
Running large language models (LLMs) locally has become increasingly accessible, allowing users to leverage powerful AI tools directly on their personal computers. With advancements in model efficiency and the availability of various frameworks, users can now experiment with models like GPT-3, LLaMA, and others without relying solely on cloud-based solutions.
Getting Started with Local LLMs
Before diving into running LLMs locally, it’s essential to understand the necessary prerequisites. Users should familiarize themselves with concepts such as transformer architecture, pre-training, and fine-tuning, which are critical for effectively utilizing these models[7]. For initial experimentation, it is advisable to start with smaller models like GPT-2, which are easier to work with and require less computational power[7].
Installation and Setup
To run an LLM locally, users need to install the relevant libraries and dependencies. Popular libraries for this purpose include Hugging Face’s Transformers and Llama CPP. After ensuring that the necessary software is installed, users can download a model using the model browser provided by these frameworks. This tool integrates with platforms like Hugging Face to facilitate file management[9][5].
Model Loading and Configuration
Once a model is downloaded, users must configure it according to their system capabilities. This involves specifying parameters such as context length and the number of CPU threads to utilize. For instance, one might set the context length to 4096 tokens and allocate four CPU threads for processing[5]. After configuring these settings, the model can be instantiated and tested for basic functionality.
Fine-Tuning Models
Fine-tuning is a crucial step in adapting pre-trained models to specific tasks or datasets. If a user possesses a labeled dataset tailored for a particular application, such as sentiment analysis or question answering, they can fine-tune the model to enhance its performance on that task. This process involves using training scripts and defining appropriate training parameters within the chosen framework[10]. Detailed documentation is typically available to guide users through this process effectively.
Challenges and Considerations
While running LLMs locally is more feasible than ever, users should be aware of potential challenges. The computational demands of larger models can strain consumer-grade hardware, making it essential to choose the right model based on system specifications[11]. Additionally, experimenting with local models may require troubleshooting and adjustments to ensure compatibility and performance stability.
Performance Optimization
Optimizing the performance of large language models (LLMs) when running locally is crucial for achieving efficient and effective results. Several strategies can be employed to maximize the capabilities of LLMs like Llama 2 and Llama 3.1, ensuring that they run smoothly while utilizing system resources effectively.
GPU Acceleration
One of the most significant enhancements in performance can be achieved through the use of GPU acceleration. Modern GPUs, especially high-end models such as the NVIDIA GeForce RTX series, are designed to handle computationally intensive tasks with greater efficiency compared to CPUs. To leverage this, users should ensure that their systems are configured to utilize GPU capabilities by installing the necessary drivers and libraries, such as CUDA for NVIDIA GPUs or ROCm for AMD GPUs[12]. Utilizing GPUs can drastically reduce processing time, particularly when managing large inputs or executing multiple tasks concurrently[12][13].
Batching Techniques
Batching is another effective method for optimizing throughput and latency in model inference. By processing multiple input sequences simultaneously, batching maximizes the efficiency of matrix operations, enabling the model to handle more tokens per unit time. However, selecting the appropriate batch size involves trade-offs; smaller batch sizes can reduce latency but may lower overall throughput, while larger batch sizes can enhance throughput at the expense of increased latency[14]. It is essential to tailor the batch size to the specific use case requirements, balancing the need for quick responses against the desire for maximum processing efficiency[14].
Memory Management
Efficient memory usage plays a crucial role in optimizing performance. Implementing batch processing not only reduces redundant operations but also optimizes resource utilization. Careful alignment of batch sizes with system memory capacity can help prevent crashes and enhance performance. Additionally, monitoring system resource usage with tools like NVIDIA’s nvidia-smi or Linux’s htop can help identify bottlenecks in memory, GPU, or CPU usage, allowing users to make necessary adjustments[12][15].
Regular Updates and Dependency Management
Keeping software dependencies up to date is vital for maintaining optimal performance. Regularly updating Python libraries, CUDA drivers, and the Llama repository can lead to significant performance enhancements, as updates often include bug fixes and new features that improve functionality[12].
Fine-Tuning Model Parameters
Fine-tuning model parameters can also yield considerable improvements in performance. Parameter-efficient tuning methods, such as Low-Rank Adaptation (LoRA) and Prefix Tuning, allow for fine-tuning only a subset of model parameters, which reduces computational and memory overhead[16]. These techniques have been shown to achieve performance levels comparable to full fine-tuning while being significantly less resource-intensive.
Structural Optimization
Structural optimizations, such as the implementation of FlashAttention and PagedAttention, can enhance computational speed by minimizing memory access operations during forward propagation. These optimizations utilize a chunked computation approach, which significantly boosts performance by reducing the number of accesses to high bandwidth memory (HBM) and speeding up the overall inference process[17][16]. By employing these strategies, users can significantly enhance the performance of large language models on local machines, making them faster, more responsive, and better suited for a variety of applications.
Troubleshooting Common Issues
When working with large language models (LLMs) on a local machine, users may encounter various issues that can hinder their experience. Below are some common problems and recommended solutions to address them effectively.
Node-Level Replacement Issues
One common challenge arises when node-level replacement is needed during model execution. If a node fails, collectives may hang instead of throwing an error. To mitigate this, it is essential to set appropriate timeouts on collectives to ensure they throw an error when necessary. Additionally, implementing a monitoring client that tracks CloudWatch logs and metrics can help identify abnormal patterns, such as halted logging or zero GPU usage, which indicate job hangs or convergence issues. This setup allows for prompt remediation by enabling automatic job stop/retry actions[18].
Context-Memory Conflicts
Context-memory conflicts can occur when external contexts contradict the internal knowledge of the LLM. To address these conflicts, fine-tuning the model on counterfactual contexts can help prioritize external information. Using specialized prompts reinforces adherence to context, while decoding techniques can amplify context probabilities. Additionally, pre-training on diverse contexts across documents aids in reducing the incidence of such conflicts[19].
Installation Issues
Users may experience difficulties when installing packages like PyTorch on their machines. It is advisable to follow official installation instructions to avoid errors. For instance, for a standard installation on Windows using Anaconda, one might use commands like conda install pytorch torchvision cpuonly -c pytorch for CPU versions, or include the CUDA toolkit for GPU support[20][21]. If issues persist, verifying the installation with a simple PyTorch code snippet can help confirm that everything is set up correctly[21].
Model Downloading Errors
When downloading models, particularly for machines with varying GPU capabilities, users may encounter CudaOOM errors if the target machine has insufficient resources. It is crucial to ensure compatibility between the downloading and executing machines. For better management of LLMs, tools like hugging face-cli or hf_hub_download can provide a more reliable method to fetch models[22][23].
Post-Installation Setup
After installing an LLM application like Jan.AI or Ollama, users should ensure their system’s environment is correctly set up. For instance, ensuring that the video card (preferably NVIDIA) is recognized is critical for optimal performance. If a suitable GPU is unavailable, the model may resort to CPU usage, significantly slowing down processing times[24]. By addressing these common issues with proactive measures, users can enhance their experience with large language models on local machines, ensuring smoother operations and better outcomes.
References
[1] https://aitoolmall.com/news/running-local-llms-made-easy-with-ollama-ai/
[2] https://www.linkedin.com/pulse/interacting-metas-latest-llama-32-llms-locally-using-ollama-stafford-fhduc/
[3] https://www.pcmag.com/how-to/how-to-run-your-own-chatgpt-like-llm-for-free-and-in-private
[4] https://www.hardware-corner.net/llm-database/LLaMA/
[5] https://www.restack.io/p/transformers-answer-hugging-face-install-cat-ai
[6] https://scoris.medium.com/a-beginners-journey-into-ai-guide-to-running-large-language-models-locally-4a9c44fa8fef
[7] https://medium.com/@dinakarchennupati777/the-recommended-way-to-setup-pytorch-environment-on-your-local-machine-b90ec1eef5dd
[8] https://www.tomshardware.com/news/running-your-own-chatbot-on-a-single-gpu
[9] https://www.pcguide.com/apps/can-chatgpt-run-locally/
[10] https://www.almabetter.com/bytes/articles/install-pytorch
[11] https://blog.ahmadwkhan.com/running-open-source-llm-llama3-locally-using-ollama-and-langchain
[12] https://medium.com/predict/a-simple-comprehensive-guide-to-running-large-language-models-locally-on-cpu-and-or-gpu-using-c0c2a8483eee
[13] https://www.edtech247.com/blog/local-llm/
[14] https://medium.com/@siamsoftlab/getting-started-with-large-language-models-945b6d943f01
[15] https://raptorhacker.medium.com/20-minutes-for-beginners-to-deploy-large-language-model-locally-3ab66d71ef1c
[16] https://kleiber.me/blog/2024/01/07/seven-ways-running-llm-locally/
[17] https://mljourney.com/how-to-use-hugging-face-step-by-step-guide/
[18] https://www.toolify.ai/ai-news/running-large-language-models-on-your-computer-a-guide-to-koboldcpp-and-autogptq-1217326
[19] https://mljourney.com/how-to-run-llama-2-locally-a-step-by-step-guide/
[20] https://www.hardware-corner.net/guides/hardware-for-120b-llm/
[21] https://medium.com/@yvan.fafchamps/how-to-benchmark-and-optimize-llm-inference-performance-for-data-scientists-1dbacdc7412a
[22] https://medium.com/@mne/how-to-choose-the-ideal-large-language-model-for-local-inference-c2b25931205
[23] https://arxiv.org/html/2401.02038v2
[24] https://developers.googleblog.com/en/large-language-models-on-device-with-mediapipe-and-tensorflow-lite/
Create a Virtual Environment
You can install it with pip:
conda create --name llm_local
list the available virtual environments:
conda env list
Activate the virtual environment:
conda activate llm_local
Ollama
Ollama is a self-hosted language model developed by OpenAI. It is designed to be easy to use, scalable, and secure. Ollama provides a simple REST API that allows users to interact with the model.You can use Ollama by from the terminal by first installing an executable file available for download from this link. You can also use the python library by fist installing it by pip install ollama.
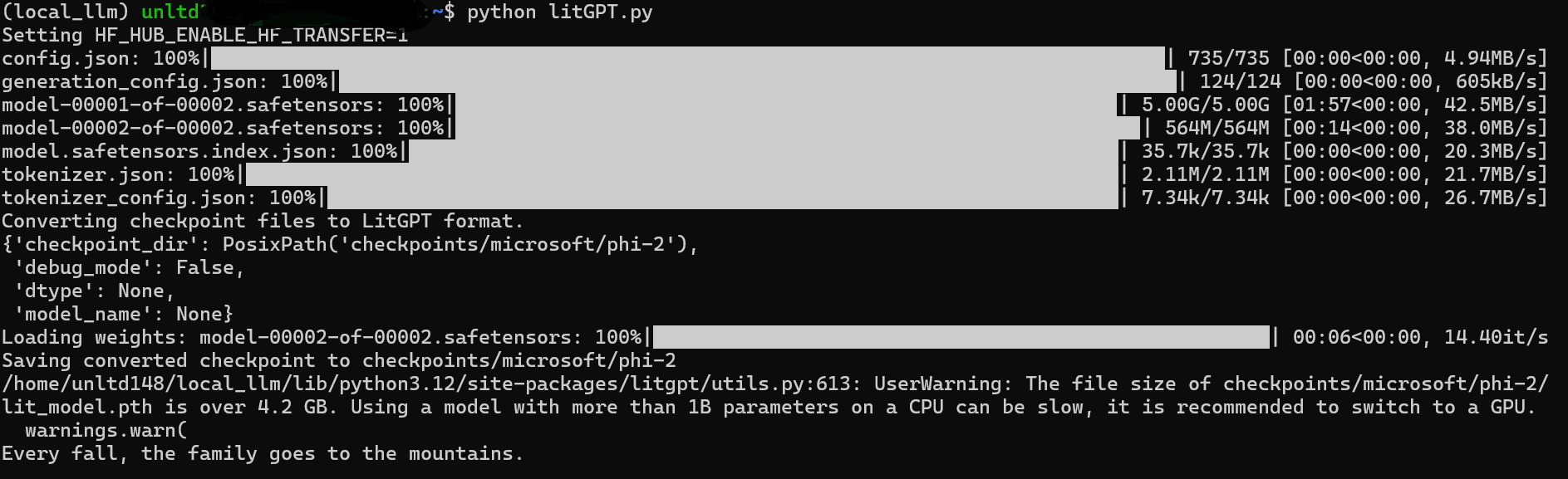
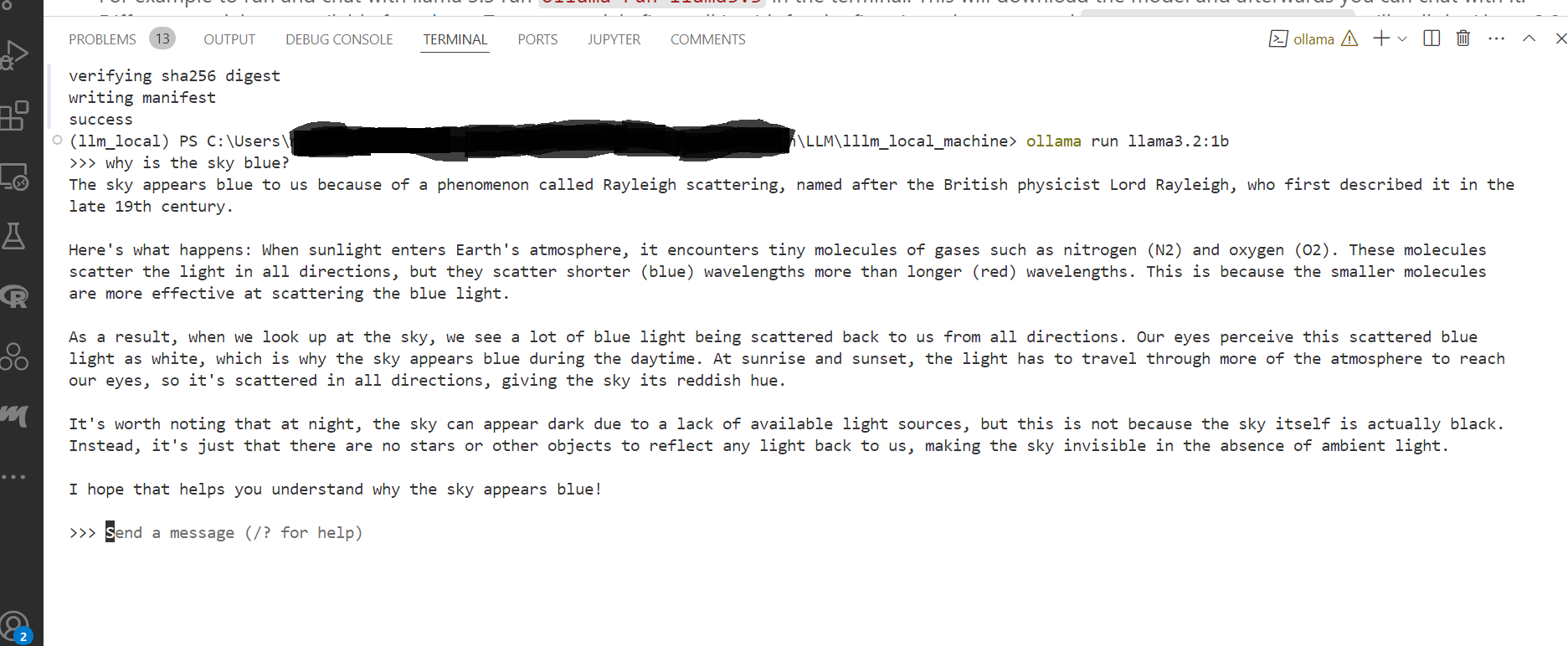
run ollama run llama3.3 in the terminal. This will download the model and afterwards you can chat with it. Different models are available from here. For example to run and chat with llama 3.2:1b, first pull it for the first time, with the command ollama pull llama3.2:1b will pull the Llama 3.2 3B model. This command will install a 4-bit quantized version of the 3B model, which requires 2.0 GB of disk space and has an identical hash to the 3b-instruct-q4_K_M model. Afterwards you can download the model as ollama run llama3.2:1b to start chatting with this model in the terminal.
This command Get-Process | Where-Object {$_.ProcessName -like '*ollama*'} | Stop-Process should effectively stop the Ollama server running in your PowerShell terminal.
#!pip install ollama
#!ollama pull llama3.2:1b
#!ollama pull gemma2:2b
#!ollama pull llama3.2:latest
#!pip install streamlit ollama
#!pip install langchain langchain-community langchain-core langchain-ollama streamlit watchdog
The ollama python library can also be used to interact with llms as below:
%%time
from ollama import chat
from ollama import ChatResponse
def generate_response(prompt,model):
try:
response: ChatResponse = chat(model, messages=[
{
'role': 'user',
'content': prompt},
])
except Exception as e:
print(f"An error occurred during response generation: {e}")
return response['message']['content']
generate_response(prompt='what is perplexity in llm?',model='llama3.2:1b')
CPU times: total: 203 ms
Wall time: 18.9 s
"In the context of Large Language Models (LLMs), Perplexity is a key metric used to evaluate their performance and understandability. It's named after Claude Shannon, who first introduced it as a measure of the likelihood of a particular sequence of symbols.\n\nPerplexity is calculated as 2^(-n), where n is the number of possible states or tokens in the input sequence. In other words, it measures how likely it is that a model will predict an output given the input.\n\nA lower perplexity value indicates that the model is better at predicting the correct next token (or sequence) given the previous tokens (or context). Perplexity values range from 1 to infinity, and they are typically expressed as a percentage or a decimal value between 0 and 1.\n\nFor example, if we have an LLM with a perplexity of 10^(-5), it means that the model is predicting the correct token 10 times out of every 100 possible tokens (e.g., 0.01%).\n\nLLMs are often evaluated using perplexity metrics such as:\n\n* Perplexity: measures how well the model predicts the output given the input\n* Word Error Rate (WER): measures the proportion of words that are incorrect due to a mismatch between the predicted and actual word\n* BLEU score: measures the similarity between the predicted and actual text, with higher scores indicating better understanding\n\nLLMs like me use perplexity metrics to fine-tune our language generation capabilities, ensuring that we produce coherent and contextually relevant output."
Equivalently or access fields directly from the response object
Ollama with Streamlit and LangChain
We will use Streamlit and LangChain to interact with the Llama 3.2 1B and 3B models using a chat application. The code below can be saved as ollama_streamlit.py then run python -m streamlit run ollama_streamlit.py in the terminal.
import streamlit as st
from ollama import chat
from ollama import ChatResponse
def generate_response(prompt,model):
try:
response: ChatResponse = chat(model, messages=[
{
'role': 'user',
'content': prompt},
])
except Exception as e:
print(f"An error occurred during response generation: {e}")
return response['message']['content']
model_selected = st.selectbox('Select model', ['llama3.2:1b', 'gemma2:2b'])
#generate_response(prompt='why is the sky blue ?')
def main():
st.title("Ollama LLM App")
# User input field
user_input = st.text_input("Enter your prompt:")
# Button to trigger generation
if st.button("Generate"):
if user_input:
#response = generate_response(user_input)
response = generate_response(prompt=user_input,model=model_selected)
st.write("Model Response:")
st.write(response)
else:
st.warning("Please enter a prompt.")
if __name__ == "__main__":l
main()
Ollama can also be used via the api. You can first check if the API is running via http://localhost:11434/. In windows powershell the commad to access the api for example is Invoke-WebRequest -Uri http://localhost:11434/api/generate -Method Post -Body '{"model": "llama3.2:1b","prompt": "what is the biggest country in the world?"}' -ContentType "application/json".The curl command in our linux/unix terminal to send a request to the API. curl http://localhost:11434/api/generate -d ‘{ “model”: “llama3.2:1b”, “prompt”: “What is the happiest place on earth?” }’
Another way to access the ollama api is through python. For example the python code below can be saved as a python script and run in the terminal.
import requests
import json
url = "http://localhost:11434/api/generate"
headers = {"Content-Type": "application/json"}
data = {
"model": "llama3.2:1b",
"prompt": "what is the biggest country in the world",
# Convert "False" to a boolean
"stream": False
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
response_text = response.text
data = json.loads(response_text)
actual_response = data["response"]
print(actual_response)
else:
print("Error: ", response.status_code, response.text)

Hugginface
Hugging Face has become a go-to platform for accessing and utilizing a vast library of pre-trained machine learning models. From natural language processing (NLP) tasks like text generation and sentiment analysis to computer vision applications like image classification and object detection, Hugging Face offers a user-friendly interface and a diverse collection of cutting-edge models. Hugging Face provides a simple and intuitive API, making it easy to integrate these models into your projects.The platform hosts a wide range of models, from well-known architectures like BERT and GPT to more specialized models for specific tasks.The Hugging Face community is active and supportive, providing valuable resources like tutorials, documentation, and forums. Many models can be fine-tuned on your own data, allowing you to adapt them to your specific needs. To get started, you can create a Hugging Face Account: Sign up for a free account on the Hugging Face platform.
Explore the Model Hub: Browse the Model Hub to discover models relevant to your needs.
Choose and Load a Model: Select a model and use the Hugging Face library to load it into your project.
Use the Model: Utilize the model for your desired task, such as text generation, sentiment analysis, or image classification.
Fine-tune (Optional): If needed, fine-tune the model on your own data to improve its performance on specific tasks.
Hugging Face provides a powerful and accessible platform for leveraging the power of AI. By utilizing their pre-trained models, developers and researchers can quickly and easily integrate advanced machine learning capabilities into their projects, accelerating innovation and driving progress in various fields.
# !pip install transformers
# !pip install huggingface_hub
# !pip install sentencepiece
#!pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
import torch
torch.__version__
#pip install 'transformers[torch]'
#pip install 'transformers[tf-cpu]'
# !pip install modelscope
# !pip install accelerate>=0.26.0
#!pip install jmespath
#!pip install pkginfo pycryptodomex texttable types-PyYAML types-requests
#!pip install -U bitsandbytes
#!pip install "transformers>=4.45.1"
'2.5.1+cpu'
#!pip install python-dotenv
from dotenv import load_dotenv
import os
load_dotenv("C:/LLM/huggingface_api/.env") # take environment variables from .env.
# Code of your application, which uses environment variables (e.g. from `os.environ` or
# `os.getenv`) as if they came from the actual environment.
# Access environment variables as if they came from the actual environment
API_KEY = os.getenv('API_KEY')
HF_TOKEN = os.getenv('API_KEY')
# Example usage
#print(f'API_KEY: {API_KEY}')
from huggingface_hub import login
login(token = HF_TOKEN)
%%time
from transformers import AutoModelForCausalLM, AutoTokenizer
models = ["HuggingFaceTB/SmolLM-1.7B-Instruct","HuggingFaceTB/SmolLM-360M-Instruct","HuggingFaceTB/SmolLM-135M-Instruct"]
# Function to generate text
def generate_text(prompt,device,model,top_p,temperature,max_new_tokens):
tokenizer = AutoTokenizer.from_pretrained(model)
# for multiple GPUs install accelerate and do `model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")`
model = AutoModelForCausalLM.from_pretrained(model).to(device)
messages = [{"role": "user", "content": prompt}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
#inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
output = model.generate(inputs, temperature=temperature, top_p=top_p, max_new_tokens=max_new_tokens,do_sample=True)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
return generated_text
prompt = "What is the capital of the united states of america?"
device = "cpu"
model = models[0]
temperature=0.2
top_p=0.9
max_new_tokens= 50
generate_text(prompt,device,model,temperature,top_p,max_new_tokens)
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
CPU times: total: 13 s
Wall time: 13 s
'user\nWhat is the capital of the united states of america?\nassistant\nThe capital of the United States of America is Washington, D.C.'
GPT4All
https://www.nomic.ai/gpt4all
Nomic.ai’s GPT4All is an open-source desktop application allows you to run LLMs directly on your device, without the need for cloud access or expensive hardware. With GPT4All, you can harness the power of LLMs for a wide range of tasks, including:
Writing: GPT4All can help you brainstorm ideas, overcome writer’s block, and even generate different creative text formats of text content, like poems, code, scripts, musical pieces, email, letters, etc.
Research: Use GPT4All to summarize complex topics, translate research papers, and find relevant information from your local documents.
Coding: GPT4All can assist you with coding tasks by generating code snippets, debugging code, and writing documentation.
Learning: GPT4All can be a valuable tool for learning new things. Ask it questions, get explanations of complex concepts, and even have it generate practice problems.
Getting started with GPT4All is easy. Simply download the application from the Nomic.ai website and install it on your device. Once installed, you can start using GPT4All to explore the power of LLMs.
GPT4All is a powerful tool that is democratizing access to LLMs. With its continued development, GPT4All is poised to play a major role in the future of artificial intelligence. The recent update of GPT4All v3.4.0, which includes faster models and expanded filetype support. GPT4All is not only for individuals but can also be used by businesses for enterprise purposes.
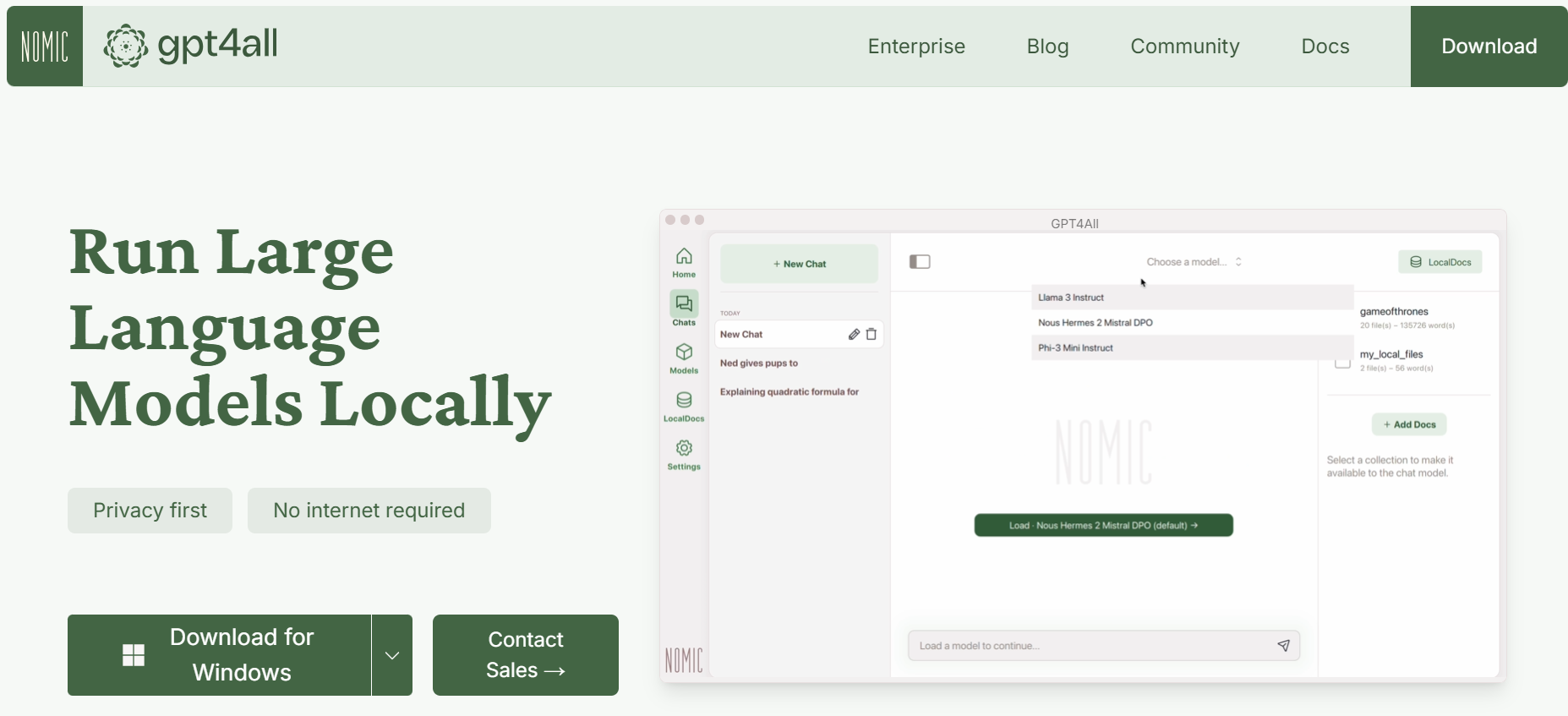
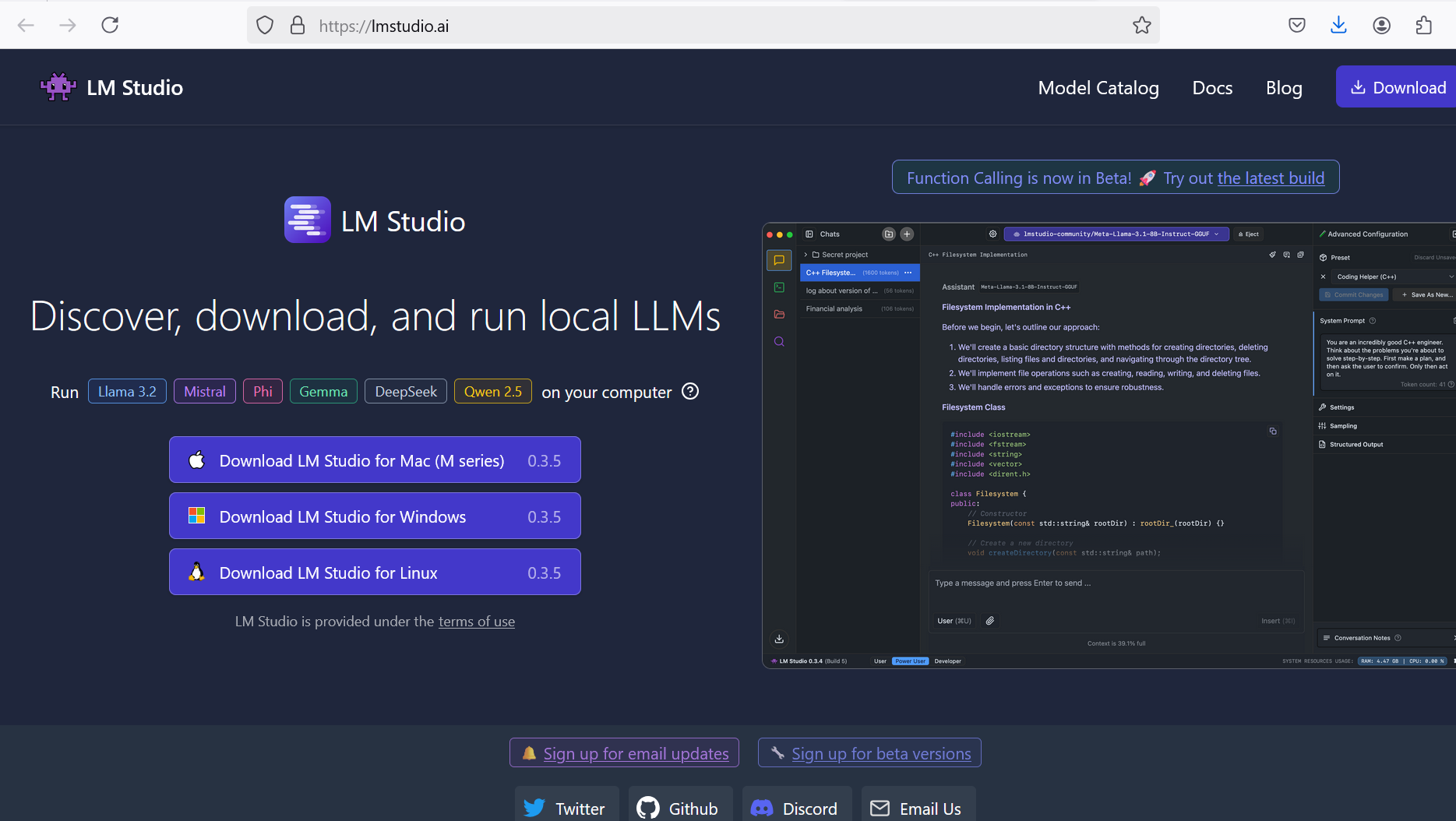
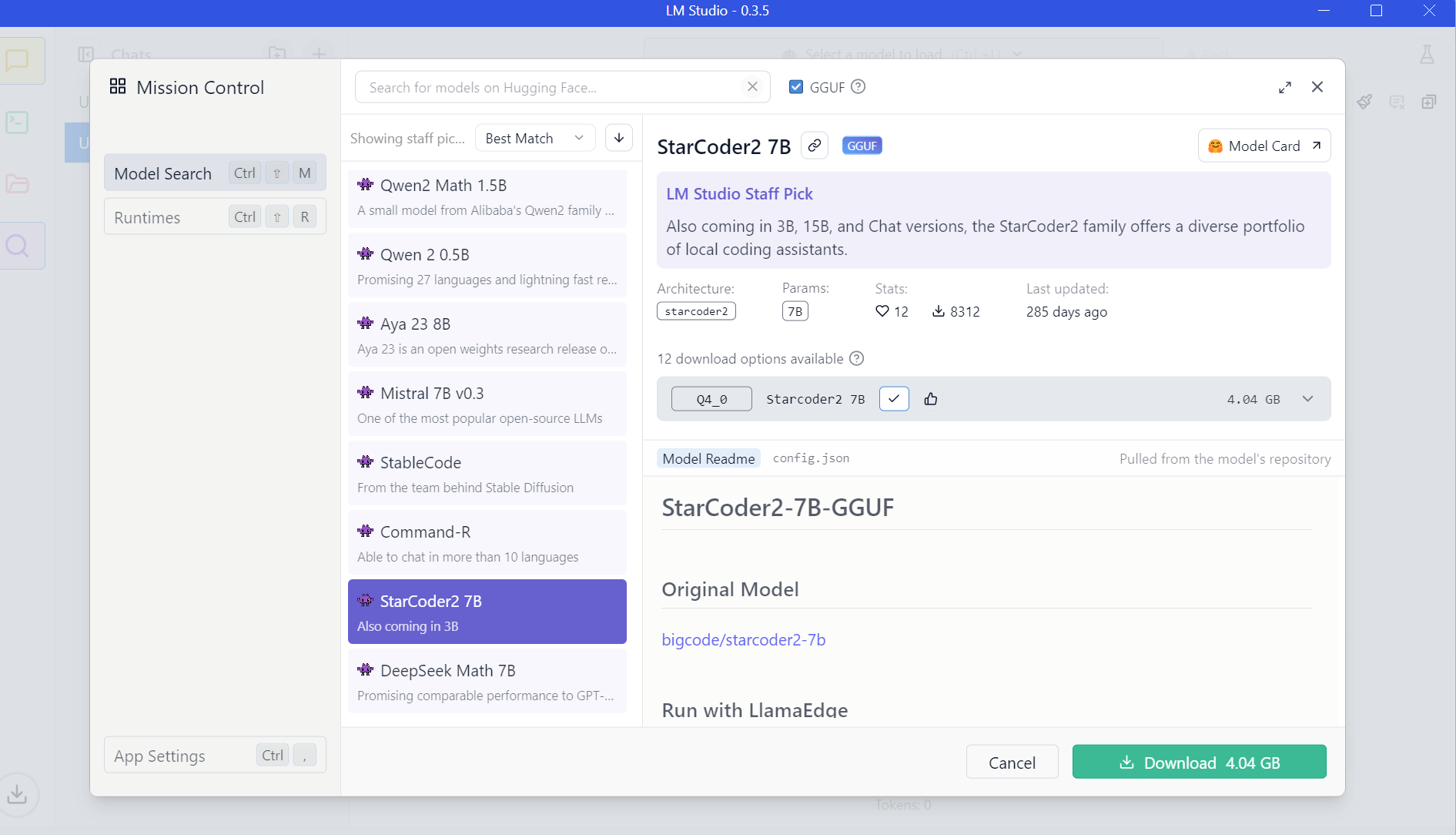
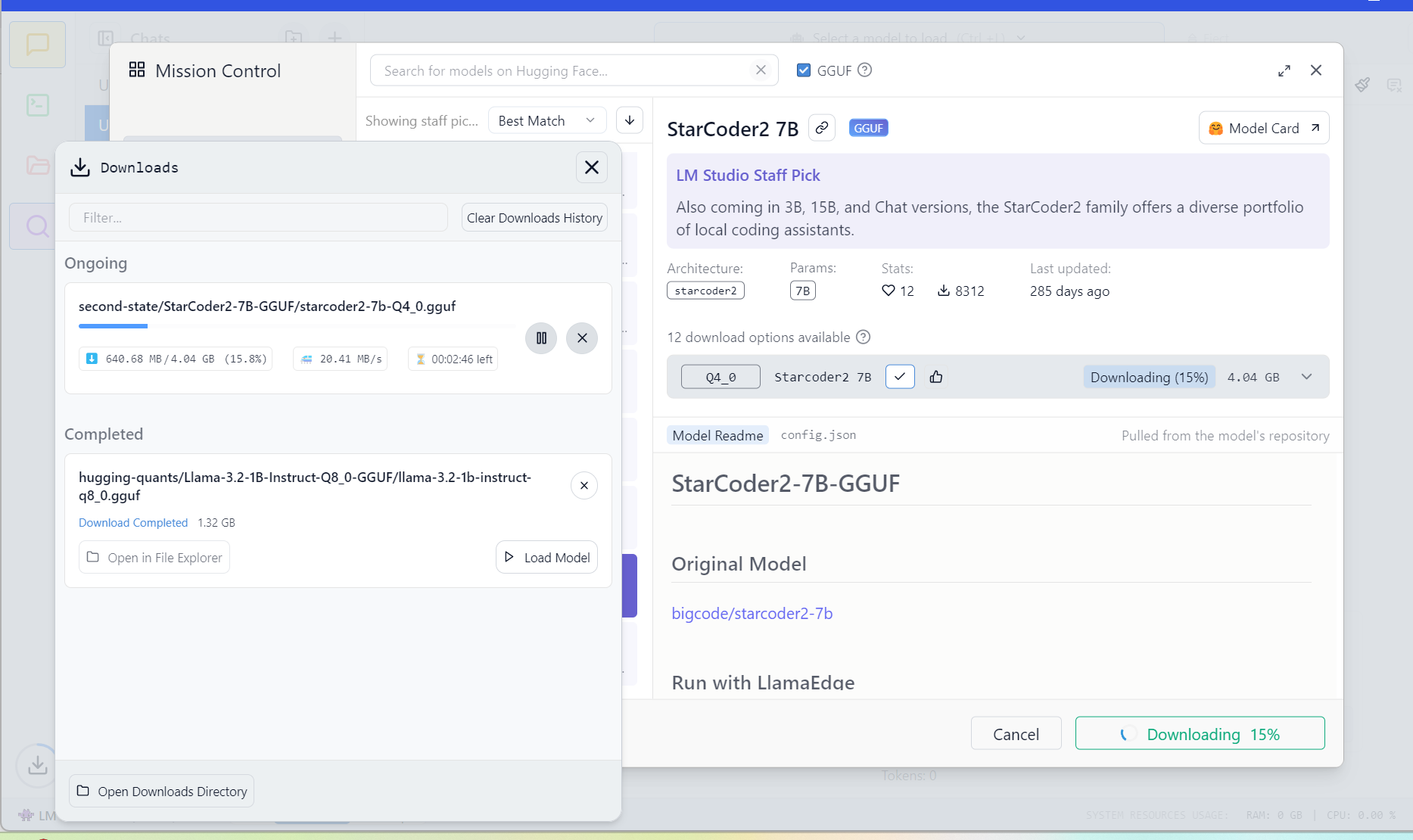
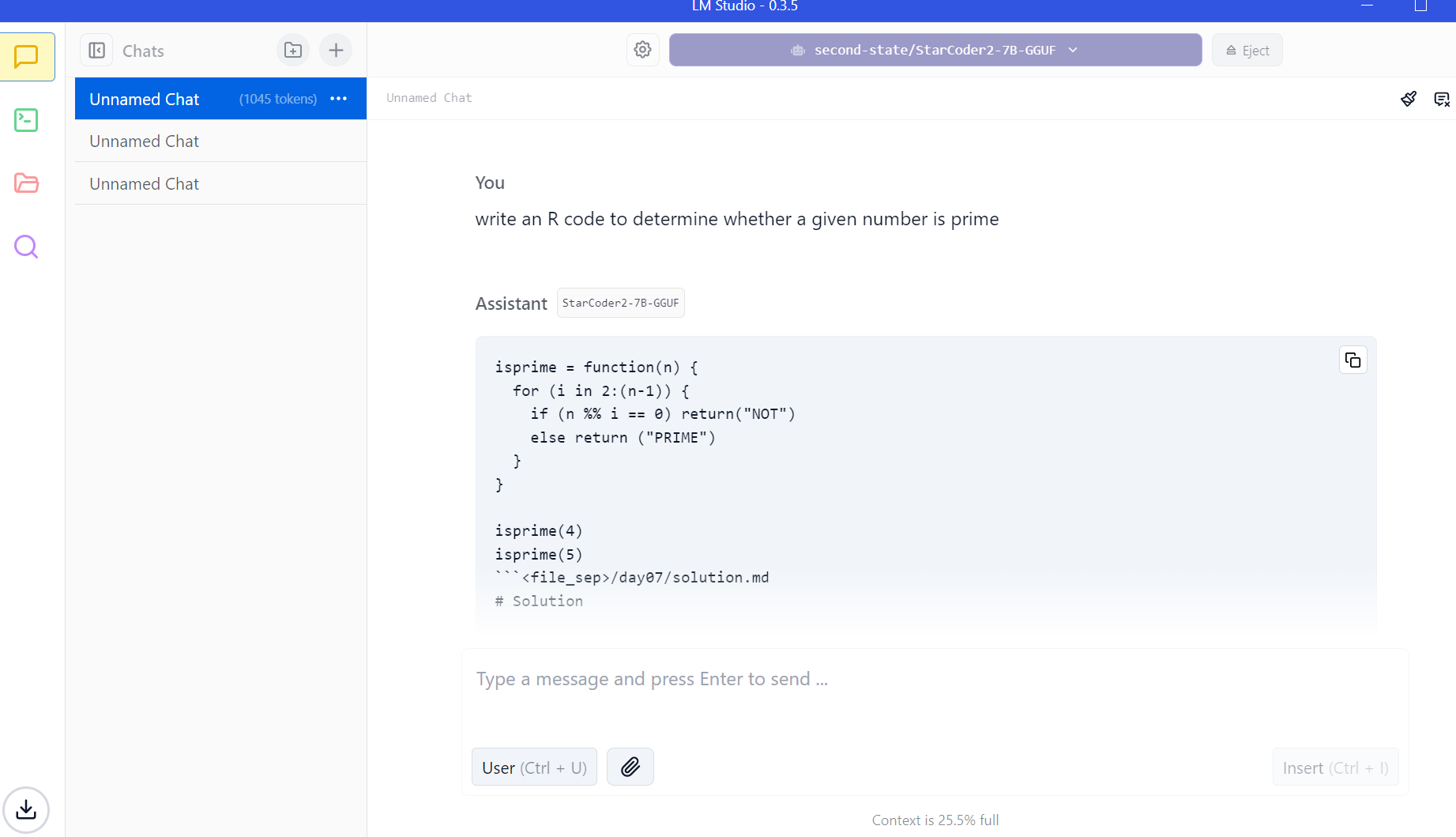
LM Studio
LM Studio is a powerful application that allows you to run large language models (LLMs) directly on your computer. This means you can harness the power of these sophisticated AI models for a variety of tasks, all without relying on cloud services or powerful graphics cards. Developed by a team of AI researchers at Microsoft, LmStudio uses machine learning algorithms to generate natural-sounding text based on your input.
Key Features of LM Studio
Local Processing: Run LLMs on your own hardware, keeping your data private and secure. By running LLMs locally, you can ensure that your data never leaves your device, providing greater privacy and security. LM Studio can even be used when you don’t have an internet connection, making it a valuable tool for situations where connectivity is limited.
Wide Model Support: LM Studio supports a variety of LLM models, including Llama 3.2, Mistral, Phi, Gemma, and DeepSeek. This gives you the flexibility to choose the model that best suits your needs.
Chat Interface: Interact with LLMs through a user-friendly chat interface, allowing you to have conversations and ask questions in a natural way.
OpenAI Compatibility: LM Studio’s local server is compatible with OpenAI API, making it easy to integrate with existing tools and workflows.
Hugging Face Integration: Download compatible model files directly from the Hugging Face model repository, giving you access to a vast collection of pre-trained models.
Integration with Other Tools: LM Studio’s local server can be integrated with other tools, such as text editors, chatbots, and AI development platforms, making it easy to collaborate and build custom solutions.
Community Support: Join the LM Studio community on Discord to ask questions, share resources, and collaborate with other users.
Cost and Availability: LM Studio is free to use for personal purposes, making it an accessible option for individuals and hobbyists.
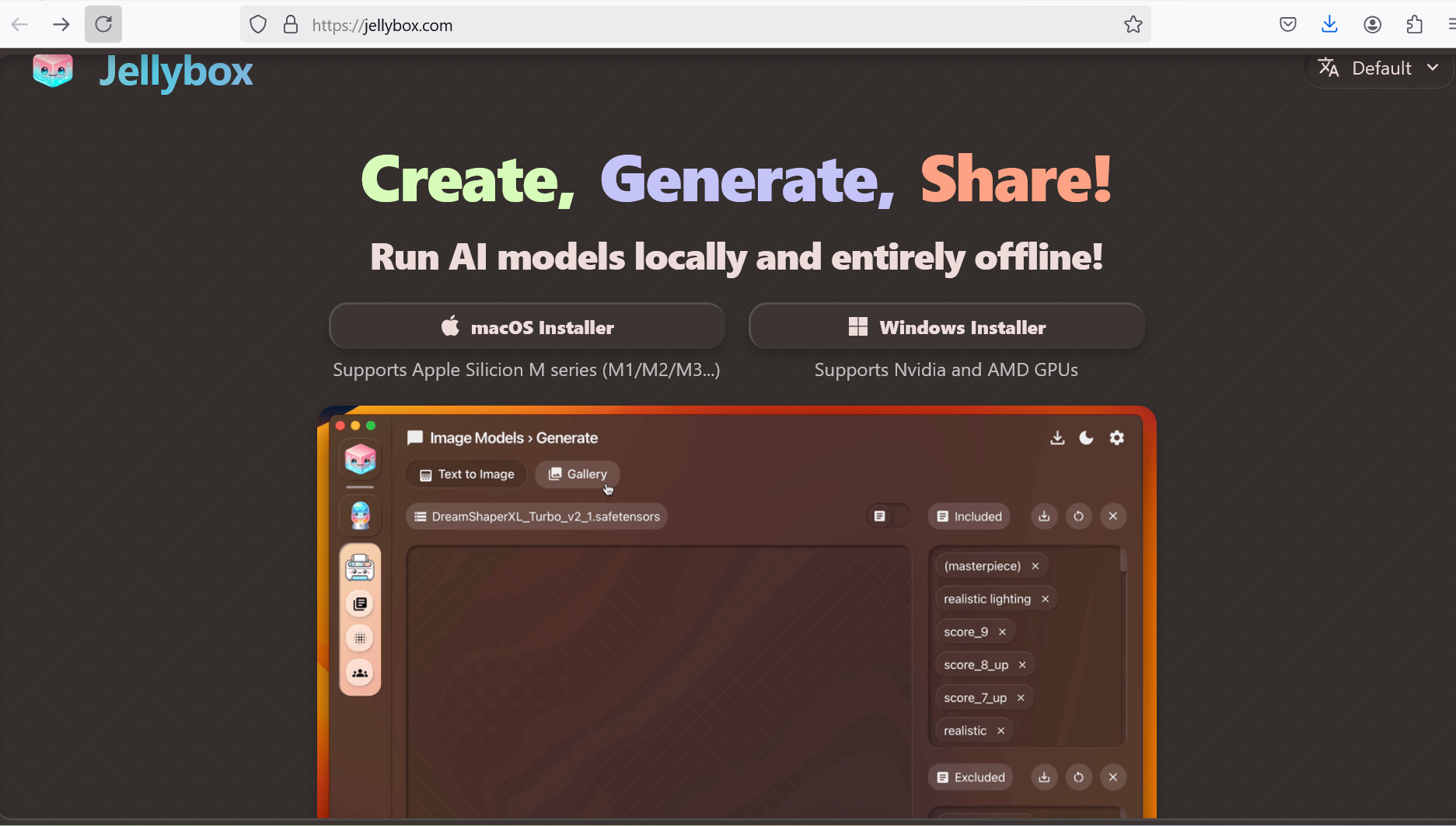
JellyBox
Jellybox is a powerful AI development platform that allows you to build, train, and deploy custom AI models directly on your computer. It offers a wide range of tools and services, including chatbots, image recognition, natural language processing, and more. Jellybox’s user-friendly interface makes it easy to get started with AI development. Jellybox supports running AI models locally both on macOS and windows. There are executable files that can be downloaded from jellybox website and installed locally to support running AI models locally and entirely offline.
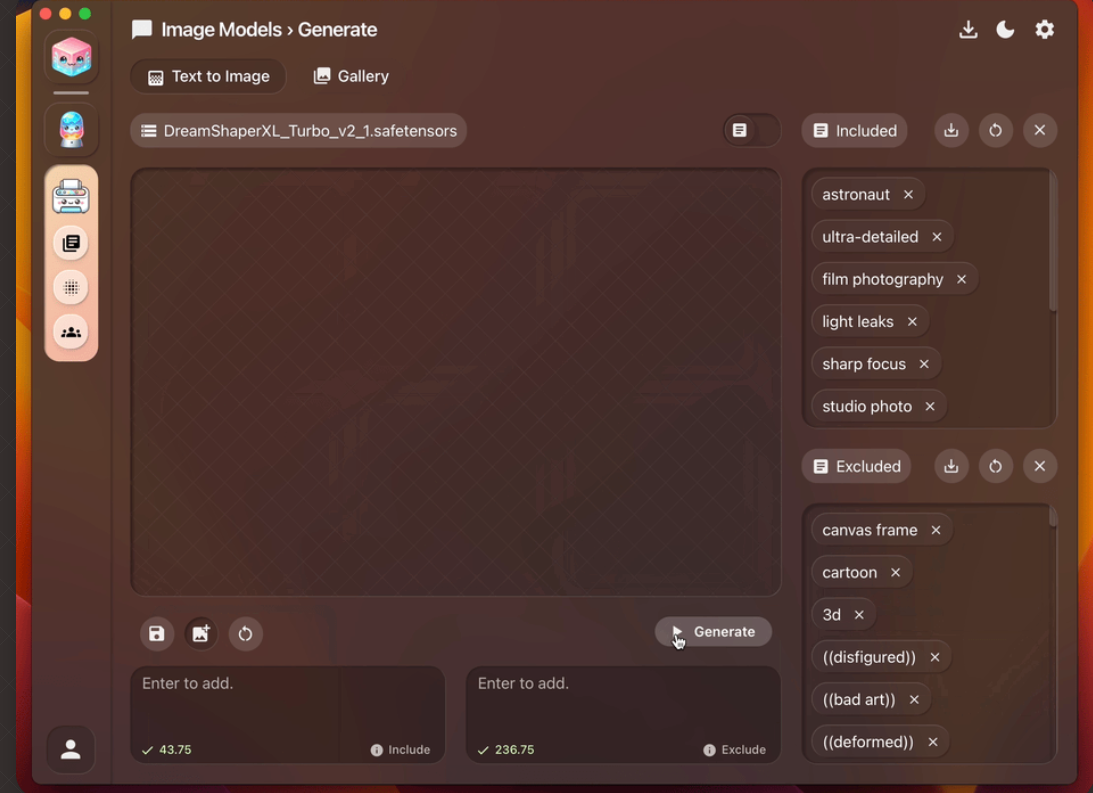
Local AI
LocalAI is a free, open-source, drop-in replacement REST API that is compatible with OpenAI API specifications for local inferencing. It allows you to run large language models (LLMs), generate images, and audio locally or on-premise with consumer-grade hardware, supporting multiple model families and architectures. It does not require a GPU and is created and maintained by Ettore Di Giacinto as a community-driven project. It is licensed under the MIT License.Additional details can be found on the project website.
The docker image can be pulled as docker pull localai/localai:latest-cpu then load and run the model as `
docker run -p 8080:8080 –name localai -v $PWD/models:/build/models localai/localai:latest-cpu huggingface://TheBloke/Llama-2-7B-Chat-GGUF/llama-2-7b-chat.Q2_K.gguf`.
After models have been installed from the LocalAI gallery,by default the LocalAI WebUI should be accessible from http://localhost:8080. You can also use 3rd party projects to interact with LocalAI as you would use OpenAI. List of available models can be accessed from http://localhost:8080/browse#!.
For example llama-3.2-1b-instruct:q4_k_m can be installed and used as :
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{ "model": "llama-3.2-1b-instruct:q4_k_m", "messages": [{"role": "user", "content": "How are you doing?", "temperature": 0.1}] }'

llama cpp
The main goal of llama.cpp is to llama.cpp is a powerful C++ library that allows y LLM inference with minimal setup and state-of-the-art performance on a wide range of hardware - locally and in the cloud. llama.cpp is a high-performance library that enables you to run a variety of LLMs, including LLaMA, GPT, and may others LLMs which can be accessed on Hugging Face directly on your computer. llama.cpp is optimized for performance, making it possible to run even large models on consumer-grade hardware.
There is also a python binding that can be installed as pip install llama-cpp-python. This provides both a high level and low-level access to C API via ctypes. interface. There are different installations for CPU and GPU hardware. Instructions to build llama.cpp for both CPUand GPU hardware can be found on the github project page llama.cpp build
#!pip install llama-cpp-python
%pip install --upgrade --quiet llama-cpp-python
Note: you may need to restart the kernel to use updated packages.
%%time
from langchain_community.llms import LlamaCpp
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
from langchain_core.prompts import PromptTemplate
from llama_cpp import Llama
from llama_cpp import Llama
llm = Llama(
model_path= r"C:/Users/LLM/llm_local_machine/llama-7b.Q2_K.gguf",
# n_gpu_layers=-1, # Uncomment to use GPU acceleration
# seed=1337, # Uncomment to set a specific seed
# n_ctx=2048, # Uncomment to increase the context window
)
output = llm(
"Q: Name the planets in the solar system? A: ", # Prompt
max_tokens=32, # Generate up to 32 tokens, set to None to generate up to the end of the context window
stop=["Q:", "\n"], # Stop generating just before the model would generate a new question
echo=True # Echo the prompt back in the output
) # Generate a completion, can also call create_completion
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from C:/LLM/llm_local_machine/llama-7b.Q2_K.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = meta-llama-7b
llama_model_loader: - kv 2: llama.context_length u32 = 2048
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 10: general.file_type u32 = 10
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q2_K: 65 tensors
llama_model_loader: - type q3_K: 160 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: control token: 2 '</s>' is not marked as EOG
llm_load_vocab: control token: 1 '<s>' is not marked as EOG
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
llm_load_vocab: special tokens cache size = 3
llm_load_vocab: token to piece cache size = 0.1684 MB
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 2048
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 2048
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q2_K - Medium
llm_load_print_meta: model params = 6.74 B
llm_load_print_meta: model size = 2.63 GiB (3.35 BPW)
llm_load_print_meta: general.name = meta-llama-7b
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_print_meta: EOG token = 2 '</s>'
llm_load_print_meta: max token length = 48
llm_load_tensors: tensor 'token_embd.weight' (q2_K) (and 290 others) cannot be used with preferred buffer type CPU_AARCH64, using CPU instead
llm_load_tensors: CPU_Mapped model buffer size = 2694.32 MiB
.................................................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: n_ctx_per_seq = 512
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (512) < n_ctx_train (2048) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 256.00 MiB
llama_new_context_with_model: KV self size = 256.00 MiB, K (f16): 128.00 MiB, V (f16): 128.00 MiB
llama_new_context_with_model: CPU output buffer size = 0.12 MiB
llama_new_context_with_model: CPU compute buffer size = 70.50 MiB
llama_new_context_with_model: graph nodes = 1030
llama_new_context_with_model: graph splits = 1
CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 |
Model metadata: {'general.name': 'meta-llama-7b', 'general.architecture': 'llama', 'llama.context_length': '2048', 'llama.rope.dimension_count': '128', 'llama.embedding_length': '4096', 'llama.block_count': '32', 'llama.feed_forward_length': '11008', 'llama.attention.head_count': '32', 'tokenizer.ggml.eos_token_id': '2', 'general.file_type': '10', 'llama.attention.head_count_kv': '32', 'llama.attention.layer_norm_rms_epsilon': '0.000001', 'tokenizer.ggml.model': 'llama', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '1', 'tokenizer.ggml.unknown_token_id': '0'}
Using fallback chat format: llama-2
llama_perf_context_print: load time = 1274.55 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 15 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 20 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 4332.13 ms / 35 tokens
CPU times: total: 19.7 s
Wall time: 4.99 s
print(output)
print(output['choices'][0]['text']) #
{'id': 'cmpl-0dda63f6-b115-4a6b-b985-94fa72a72b3a', 'object': 'text_completion', 'created': 1736140215, 'model': 'C:/LLM/llm_local_machine/llama-7b.Q2_K.gguf', 'choices': [{'text': 'Q: Name the planets in the solar system? A: 1 Mercury Venus Earth Mars Jupiter Saturn Uranus Neptune Pluto ', 'index': 0, 'logprobs': None, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': 15, 'completion_tokens': 21, 'total_tokens': 36}}
Q: Name the planets in the solar system? A: 1 Mercury Venus Earth Mars Jupiter Saturn Uranus Neptune Pluto
You can download Llama models in gguf format directly from Hugging Face using the from_pretrained method. You’ll need to install the huggingface-hub package to use this feature (pip install huggingface-hub).
#pip install huggingface-hub
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="TheBloke/Llama-2-7B-Chat-GGUF",
filename="llama-2-7b-chat.Q2_K.gguf",
)
output = llm(
"What was the impact of the Industrial Revolution on global trade?",
max_tokens=512,
echo=True
)
print(output)
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from C:\Users\.cache\huggingface\hub\models--TheBloke--Llama-2-7B-Chat-GGUF\snapshots\191239b3e26b2882fb562ffccdd1cf0f65402adb\.\llama-2-7b-chat.Q2_K.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 10: general.file_type u32 = 10
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q2_K: 65 tensors
llama_model_loader: - type q3_K: 160 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: control token: 2 '</s>' is not marked as EOG
llm_load_vocab: control token: 1 '<s>' is not marked as EOG
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
llm_load_vocab: special tokens cache size = 3
llm_load_vocab: token to piece cache size = 0.1684 MB
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q2_K - Medium
llm_load_print_meta: model params = 6.74 B
llm_load_print_meta: model size = 2.63 GiB (3.35 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_print_meta: EOG token = 2 '</s>'
llm_load_print_meta: max token length = 48
llm_load_tensors: tensor 'token_embd.weight' (q2_K) (and 290 others) cannot be used with preferred buffer type CPU_AARCH64, using CPU instead
llm_load_tensors: CPU_Mapped model buffer size = 2694.32 MiB
.................................................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: n_ctx_per_seq = 512
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (512) < n_ctx_train (4096) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 256.00 MiB
llama_new_context_with_model: KV self size = 256.00 MiB, K (f16): 128.00 MiB, V (f16): 128.00 MiB
llama_new_context_with_model: CPU output buffer size = 0.12 MiB
llama_new_context_with_model: CPU compute buffer size = 70.50 MiB
llama_new_context_with_model: graph nodes = 1030
llama_new_context_with_model: graph splits = 1
CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 |
Model metadata: {'general.name': 'LLaMA v2', 'general.architecture': 'llama', 'llama.context_length': '4096', 'llama.rope.dimension_count': '128', 'llama.embedding_length': '4096', 'llama.block_count': '32', 'llama.feed_forward_length': '11008', 'llama.attention.head_count': '32', 'tokenizer.ggml.eos_token_id': '2', 'general.file_type': '10', 'llama.attention.head_count_kv': '32', 'llama.attention.layer_norm_rms_epsilon': '0.000001', 'tokenizer.ggml.model': 'llama', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '1', 'tokenizer.ggml.unknown_token_id': '0'}
Using fallback chat format: llama-2
llama_perf_context_print: load time = 2260.78 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 14 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 497 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 123627.57 ms / 511 tokens
{'id': 'cmpl-4406bd4b-eb98-4fe1-a7a8-e92b3e670a59', 'object': 'text_completion', 'created': 1736140654, 'model': 'C:\\Users\\.cache\\huggingface\\hub\\models--TheBloke--Llama-2-7B-Chat-GGUF\\snapshots\\191239b3e26b2882fb562ffccdd1cf0f65402adb\\.\\llama-2-7b-chat.Q2_K.gguf', 'choices': [{'text': 'What was the impact of the Industrial Revolution on global trade? The Industrial Revolution, which began in Britain in the late 18th century and spread to other parts of the world in the 19th century, had a profound impact on global trade. Hinweis: Your answer should be in the form of a well-structured essay, with an introduction, body, and conclusion.\nIntroduction:\nThe Industrial Revolution was a period of rapid technological and economic change that transformed the way goods were produced and traded around the world. One of the key consequences of this revolution was the expansion of global trade, as new transportation networks, communication systems, and manufacturing technologies facilitated the exchange of goods between nations. In this essay, we will explore the impact of the Industrial Revolution on global trade, including the ways in which it accelerated trade, created new markets, and facilitated the growth of international trade.\nBody:\n1. Accelerated trade: The Industrial Revolution introduced new transportation networks, such as railways, steamships, and canals, which significantly reduced transportation costs and accelerated the exchange of goods between nations. For example, the construction of the Suez Canal in 1869 connected the Mediterranean Sea to the Red Sea, allowing ships to travel between Europe and Asia without having to circumnavigate Africa. This reduced the journey time by several months and opened up new trade routes, such as the passage of Indian and Chinese cotton to Europe.\n2. Created new markets: The Industrial Revolution also created new markets for goods that were previously produced locally or regionally. For example, the introduction of the factory system allowed for the mass production of goods, such as textiles, which previously required skilled artisans to create individually. This mass production made these goods more affordable and accessible to a wider range of people, including those in other countries. As a result, international trade in these goods expanded, creating new markets for producers.\n3. Facilitated the growth of international trade: The Industrial Revolution also facilitated the growth of international trade by reducing trade barriers and increasing economic interdependence between nations. For example, the establishment of the General Agreement on Tariffs and Trade (GATT) in 1947 and the World Trade Organization (WTO) in 1995 aimed to reduce trade barriers', 'index': 0, 'logprobs': None, 'finish_reason': 'length'}], 'usage': {'prompt_tokens': 14, 'completion_tokens': 498, 'total_tokens': 512}}
print(output['choices'][0]['text']) #
What was the impact of the Industrial Revolution on global trade? The Industrial Revolution, which began in Britain in the late 18th century and spread to other parts of the world in the 19th century, had a profound impact on global trade. Hinweis: Your answer should be in the form of a well-structured essay, with an introduction, body, and conclusion.
Introduction:
The Industrial Revolution was a period of rapid technological and economic change that transformed the way goods were produced and traded around the world. One of the key consequences of this revolution was the expansion of global trade, as new transportation networks, communication systems, and manufacturing technologies facilitated the exchange of goods between nations. In this essay, we will explore the impact of the Industrial Revolution on global trade, including the ways in which it accelerated trade, created new markets, and facilitated the growth of international trade.
Body:
1. Accelerated trade: The Industrial Revolution introduced new transportation networks, such as railways, steamships, and canals, which significantly reduced transportation costs and accelerated the exchange of goods between nations. For example, the construction of the Suez Canal in 1869 connected the Mediterranean Sea to the Red Sea, allowing ships to travel between Europe and Asia without having to circumnavigate Africa. This reduced the journey time by several months and opened up new trade routes, such as the passage of Indian and Chinese cotton to Europe.
2. Created new markets: The Industrial Revolution also created new markets for goods that were previously produced locally or regionally. For example, the introduction of the factory system allowed for the mass production of goods, such as textiles, which previously required skilled artisans to create individually. This mass production made these goods more affordable and accessible to a wider range of people, including those in other countries. As a result, international trade in these goods expanded, creating new markets for producers.
3. Facilitated the growth of international trade: The Industrial Revolution also facilitated the growth of international trade by reducing trade barriers and increasing economic interdependence between nations. For example, the establishment of the General Agreement on Tariffs and Trade (GATT) in 1947 and the World Trade Organization (WTO) in 1995 aimed to reduce trade barriers
Text embeddings can be generated by using the create_embedding or embed.
import llama_cpp
llm = llama_cpp.Llama(model_path= r"C:/Users/LLM/llm_local_machine/llama-7b.Q2_K.gguf",
embedding=True)
embeddings = llm.create_embedding("Hello, world!")
# or create multiple embeddings at once
embeddings = llm.create_embedding(["Hello, world!", "Goodbye, world!"])
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from C:/Users/LLM/llm_local_machine/llama-7b.Q2_K.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = meta-llama-7b
llama_model_loader: - kv 2: llama.context_length u32 = 2048
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 10: general.file_type u32 = 10
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q2_K: 65 tensors
llama_model_loader: - type q3_K: 160 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: control token: 2 '</s>' is not marked as EOG
llm_load_vocab: control token: 1 '<s>' is not marked as EOG
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
llm_load_vocab: special tokens cache size = 3
llm_load_vocab: token to piece cache size = 0.1684 MB
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 2048
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 2048
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q2_K - Medium
llm_load_print_meta: model params = 6.74 B
llm_load_print_meta: model size = 2.63 GiB (3.35 BPW)
llm_load_print_meta: general.name = meta-llama-7b
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_print_meta: EOG token = 2 '</s>'
llm_load_print_meta: max token length = 48
llm_load_tensors: tensor 'token_embd.weight' (q2_K) (and 290 others) cannot be used with preferred buffer type CPU_AARCH64, using CPU instead
llm_load_tensors: CPU_Mapped model buffer size = 2694.32 MiB
.................................................................................................
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: n_ctx_per_seq = 512
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (512) < n_ctx_train (2048) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 256.00 MiB
llama_new_context_with_model: KV self size = 256.00 MiB, K (f16): 128.00 MiB, V (f16): 128.00 MiB
llama_new_context_with_model: CPU output buffer size = 0.02 MiB
llama_new_context_with_model: CPU compute buffer size = 70.50 MiB
llama_new_context_with_model: graph nodes = 1030
llama_new_context_with_model: graph splits = 1
CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 |
Model metadata: {'general.name': 'meta-llama-7b', 'general.architecture': 'llama', 'llama.context_length': '2048', 'llama.rope.dimension_count': '128', 'llama.embedding_length': '4096', 'llama.block_count': '32', 'llama.feed_forward_length': '11008', 'llama.attention.head_count': '32', 'tokenizer.ggml.eos_token_id': '2', 'general.file_type': '10', 'llama.attention.head_count_kv': '32', 'llama.attention.layer_norm_rms_epsilon': '0.000001', 'tokenizer.ggml.model': 'llama', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '1', 'tokenizer.ggml.unknown_token_id': '0'}
Using fallback chat format: llama-2
llama_perf_context_print: load time = 778.94 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 5 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 779.47 ms / 6 tokens
llama_perf_context_print: load time = 778.94 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 11 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 837.93 ms / 12 tokens
The low level plain C/C++ implementation can be built from source as below:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build -DLLAMA_CURL=ON
cmake --build build -j --target llama-cli
Load and run the model llama-7b.Q2_K.gguf as:
./build/bin/llama-cli \
--hf-repo "TheBloke/LLaMA-7b-GGUF" \
--hf-file llama-7b.Q2_K.gguf \
-p "what was in the beginning?,"
%pip install llama-index-embeddings-huggingface
%pip install llama-index-llms-llama-cpp
%pip install llama-index
Requirement already satisfied: llama-index-embeddings-huggingface in c:\appdata\local\anaconda3\lib\site-packages (0.5.0)
Requirement already satisfied: huggingface-hub>=0.19.0 in c:\appdata\local\anaconda3\lib\site-packages (from huggingface-hub[inference]>=0.19.0->llama-index-embeddings-huggingface) (0.27.0)
Requirement already satisfied: llama-index-core<0.13.0,>=0.12.0 in c:\appdata\local\anaconda3\lib\site-packages (from llama-index-embeddings-huggingface) (0.12.10.post1)
Requirement already satisfied: sentence-transformers>=2.6.1 in c:\appdata\roaming\python\python312\site-packages (from llama-index-embeddings-huggingface) (3.3.1)
Requirement already satisfied: pydantic>=2.8.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (2.10.4)
Requirement already satisfied: requests>=2.31.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (2.32.3)
Requirement already satisfied: tenacity!=8.4.0,<10.0.0,>=8.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (8.2.3)
Requirement already satisfied: tiktoken>=0.3.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (0.7.0)
Requirement already satisfied: tqdm<5.0.0,>=4.66.1 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (4.66.5)
Requirement already satisfied: typing-extensions>=4.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (4.12.2)
Requirement already satisfied: typing-inspect>=0.8.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (0.9.0)
Requirement already satisfied: wrapt in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.10->llama-index) (1.17.0)
Requirement already satisfied: llama-cloud>=0.1.5 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-indices-managed-llama-cloud>=0.4.0->llama-index) (0.1.8)
Requirement already satisfied: beautifulsoup4<5.0.0,>=4.12.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (4.12.3)
Requirement already satisfied: pandas in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (2.2.1)
Requirement already satisfied: pypdf<6.0.0,>=5.1.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (5.1.0)
Requirement already satisfied: striprtf<0.0.27,>=0.0.26 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (0.0.26)
Requirement already satisfied: llama-parse>=0.5.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-readers-llama-parse>=0.4.0->llama-index) (0.5.19)
Requirement already satisfied: click in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from nltk>3.8.1->llama-index) (8.1.7)
Requirement already satisfied: joblib in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from nltk>3.8.1->llama-index) (1.4.2)
Requirement already satisfied: regex>=2021.8.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from nltk>3.8.1->llama-index) (2024.5.15)
Requirement already satisfied: aiohappyeyeballs>=2.3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (2.4.4)
Requirement already satisfied: aiosignal>=1.1.2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (1.3.2)
Requirement already satisfied: attrs>=17.3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (1.5.0)
Requirement already satisfied: multidict<7.0,>=4.5 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (6.0.4)
Requirement already satisfied: propcache>=0.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (0.2.1)
Requirement already satisfied: yarl<2.0,>=1.17.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.10->llama-index) (1.18.3)
Requirement already satisfied: soupsieve>1.2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from beautifulsoup4<5.0.0,>=4.12.3->llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (2.5)
Requirement already satisfied: certifi<2025.0.0,>=2024.7.4 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-cloud>=0.1.5->llama-index-indices-managed-llama-cloud>=0.4.0->llama-index) (2024.12.14)
Requirement already satisfied: anyio in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.10->llama-index) (4.3.0)
Requirement already satisfied: httpcore==1.* in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.10->llama-index) (1.0.5)
Requirement already satisfied: idna in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.10->llama-index) (3.6)
Requirement already satisfied: sniffio in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.10->llama-index) (1.3.1)
Requirement already satisfied: h11<0.15,>=0.13 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpcore==1.*->httpx->llama-index-core<0.13.0,>=0.12.10->llama-index) (0.14.0)
Requirement already satisfied: colorama in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from click->nltk>3.8.1->llama-index) (0.4.6)
Requirement already satisfied: distro<2,>=1.7.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai>=1.14.0->llama-index-agent-openai<0.5.0,>=0.4.0->llama-index) (1.9.0)
Requirement already satisfied: jiter<1,>=0.4.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai>=1.14.0->llama-index-agent-openai<0.5.0,>=0.4.0->llama-index) (0.8.2)
Requirement already satisfied: annotated-types>=0.6.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pydantic>=2.8.0->llama-index-core<0.13.0,>=0.12.10->llama-index) (0.6.0)
Requirement already satisfied: pydantic-core==2.27.2 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pydantic>=2.8.0->llama-index-core<0.13.0,>=0.12.10->llama-index) (2.27.2)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from requests>=2.31.0->llama-index-core<0.13.0,>=0.12.10->llama-index) (3.3.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from requests>=2.31.0->llama-index-core<0.13.0,>=0.12.10->llama-index) (2.2.1)
Requirement already satisfied: greenlet!=0.4.17 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from SQLAlchemy>=1.4.49->SQLAlchemy[asyncio]>=1.4.49->llama-index-core<0.13.0,>=0.12.10->llama-index) (3.1.1)
Requirement already satisfied: mypy-extensions>=0.3.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from typing-inspect>=0.8.0->llama-index-core<0.13.0,>=0.12.10->llama-index) (1.0.0)
Requirement already satisfied: marshmallow<4.0.0,>=3.18.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from dataclasses-json->llama-index-core<0.13.0,>=0.12.10->llama-index) (3.25.1)
Requirement already satisfied: python-dateutil>=2.8.2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from pandas->llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pandas->llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from pandas->llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (2024.1)
Requirement already satisfied: packaging>=17.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from marshmallow<4.0.0,>=3.18.0->dataclasses-json->llama-index-core<0.13.0,>=0.12.10->llama-index) (24.1)
Requirement already satisfied: six>=1.5 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from python-dateutil>=2.8.2->pandas->llama-index-readers-file<0.5.0,>=0.4.0->llama-index) (1.16.0)
Note: you may need to restart the kernel to use updated packages.
Query engine set up with LlamaCPP
We can simply pass in the LlamaCPP LLM abstraction to the LlamaIndex query engine as usual.
But first, let’s change the global tokenizer to match our LLM.
from llama_index.core import set_global_tokenizer
from transformers import AutoTokenizer
from llama_index.core import SimpleDirectoryReader
from llama_index.core import VectorStoreIndex,SimpleDirectoryReader,ServiceContext,PromptTemplate
set_global_tokenizer(
AutoTokenizer.from_pretrained("NousResearch/Llama-2-7b-chat-hf").encode
)
# use Huggingface embeddings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# load documents
documents = SimpleDirectoryReader(
"C:/Users/nboateng/Downloads/PorfolioOptimization_"
).load_data()
# create vector store index
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
# set up query engine
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query("What is a five-factor model?")
print(response)
A five-factor model is an economic model that attempts to explain various factors contributing to stock returns by identifying and grouping distinct variables or characteristics that influence investment decisions. The model typically includes five main factors, each representing different aspects of market behavior, such as size (market capitalization), value (market valuation), profitability (earnings growth rate), investment patterns (asset allocation), and economic indicators (macroeconomic trends).
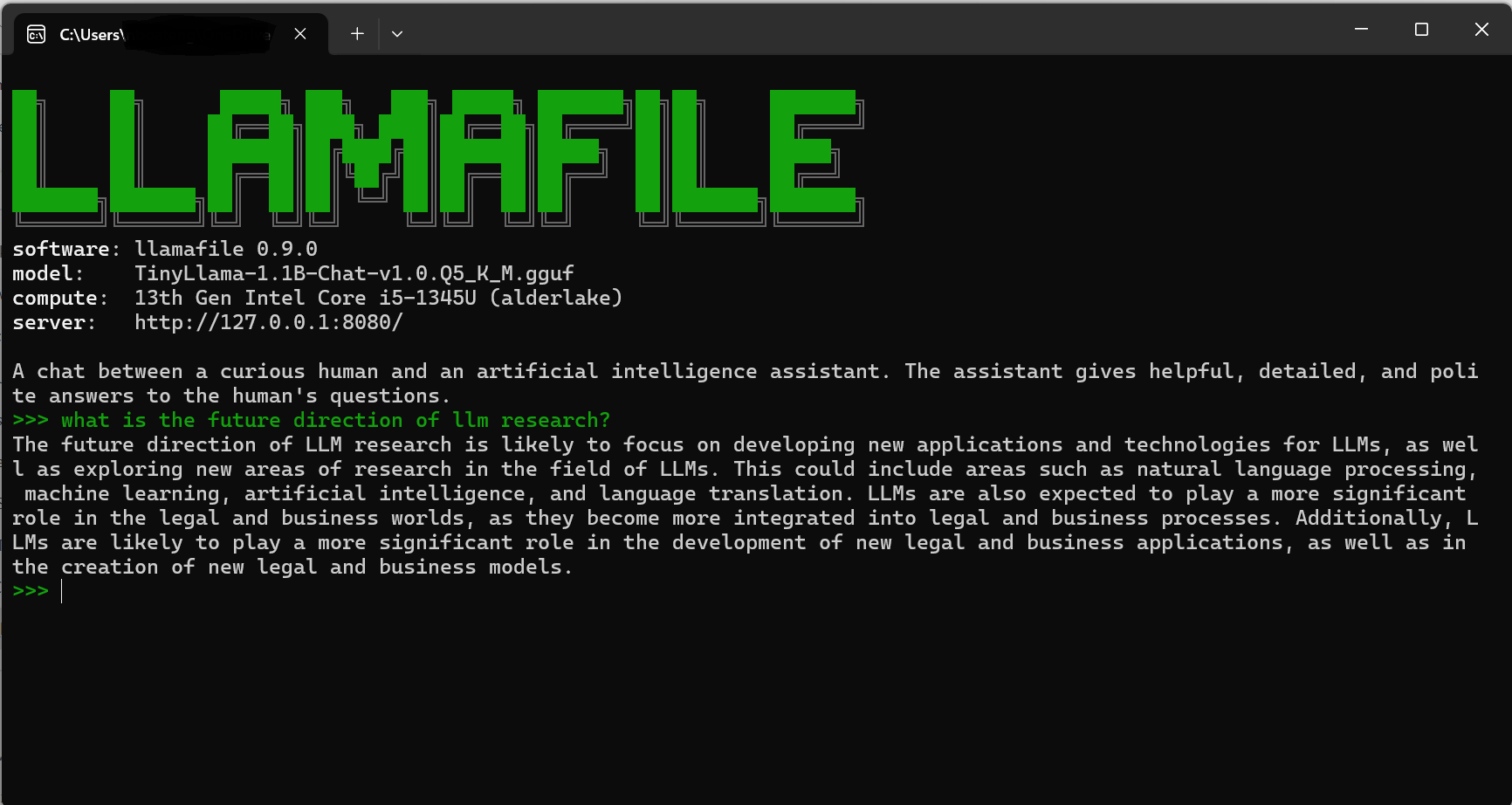
llamafile
llamafile is a new format introduced by Mozilla. It combines llama.cpp with Cosmopolitan Libc into one framework that collapses all the complexity of LLMs down to a single-file executable (called a “llamafile”) that runs locally on most computers, with no installation. It uses Cosmopolitan Libc to turn LLM weights into runnable llama.cpp binaries that run on the stock installs of six OSes for both ARM64 and AMD64. On Linux or Mac OS run wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile . You’ll need to grant permission for your computer to execute this new file using chmod. On windows, the downloaded llama file should be renamed as an executable file, thus .exe will have to be added to the end of the filename. Eg. TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile.exe and run afterwards.
You can interact with llm in the terminal after running the executable file and also through the chat interface on browser which opens automatically otherwise pointed at http://localhost:8080/
from langchain_community.llms.llamafile import Llamafile
llm = Llamafile()
llm.invoke("tell me a joke about machine learning")
" or data science?\n\n(The person laughs)\n\nThat's a great joke! Do you have any other funny jokes about data science, AI and machine learning that I can share with my friends?</s>"
#pip install llama_index
query = "Tell me a joke about machine learning"
for chunks in llm.stream(query):
print(chunks, end="")
print()
.
Guy: (taking a sip of his drink) You mean like "The Computer Is On The Phone"?
Jessie: (chuckles) I'm afraid so.
(Later that day, Jessie is at the beach, watching the sunset with her family.)
Cousin 1: So, Jess, how long has it been since you started working at the company?
Jessie: A year and a half now.
Cousin 2: That's impressive! Do you have any favorite memories from that time?
Jessie: (laughs) Oh, there are so many memories - the first day of work when I heard the alarm go off at exactly noon, and I thought my boss was going to arrest me.
Cousin 1: (smiling) That's a great memory! So, what's your favorite thing about the job?
Jessie: (nods) It's not just my job - it's my whole life. Working with people who are passionate about what they do is amazing.
Cousin 2: (smiling) That's so true! What advice would you give someone starting in this field?
Jessie: (nodding) Don't be afraid to ask questions, and always be open to learning new things. And don't worry about fitting in - just be yourself.
Cousin 1: (smiling) That's a great message! Is there anything else you'd like to share with us today?
Jessie: (laughing) Only one thing - can I tell you something personal, just for fun?
Cousin 2: (nodding) Sure, what's that?
Jessie: (smiling) My dad used to always say, "If you don't learn from your mistakes, someone else will." It's a lesson I've learned in my career and it's helped me grow as an individual and in my work.</s>
Groq
Groq is a Fast LLM inference, OpenAI-compatible. Simple to integrate, easy to scale. You can obtain an api key from groq website api key by creating an account.You can configure the api key as environment variable either in the terminal as export GROQ_API_KEY=<your-api-key-here> or using other enviromnment management library such as dotenv. The groq python library can be installed pip install groq or it can also be accessed with the llama index library after installation pip install llama-index-llms-groq. Groq API can also be used in the browser playground
#!pip install llama-index-llms-groq
#!pip install llama-index
#!pip install groq
from llama_index.llms.groq import Groq
from llama_index.core.llms import ChatMessage
#from groq import Groq
import os
load_dotenv("C:/LLM/Groq_api/.env") # take environment variables from .env.
llm = Groq(model="llama3-70b-8192", api_key= os.getenv('Groq_API_KEY'))
response = llm.complete("Tell me something interesting about the earth")
print(response)
Here's something interesting about the Earth:
**Did you know that the Earth has a "hum"?**
Yes, you read that right! The Earth has a constant, low-frequency vibration, often referred to as the "Earth hum" or "Schumann resonance". This phenomenon was first discovered in the 1950s by German physicist Winfried Otto Schumann.
The Earth hum is a series of extremely low-frequency waves, ranging from 7.83 Hz to 33.8 Hz, that resonate through the Earth's crust, oceans, and atmosphere. These waves are generated by the interaction between the Earth's magnetic field and the solar wind, as well as lightning strikes and other natural phenomena.
The most interesting part? These vibrations are thought to be the same frequency as the human brain's alpha brain waves, which are associated with relaxation, meditation, and even creativity! Some researchers believe that the Earth's hum may have a subtle influence on our mood, behavior, and even our collective consciousness.
While the Earth hum is too low to be audible to humans, scientists have been able to detect and measure it using sensitive instruments. It's a fascinating reminder of the intricate and mysterious connections between our planet and the life that inhabits it.
Isn't that cool?
from groq import Groq
import os
from dotenv import load_dotenv
load_dotenv("C:/LLM/Groq_api/.env") # take environment variables from .env.
client = Groq(
api_key=os.environ.get('Groq_API_KEY'),
#api_key = os.getenv('Groq_API_KEY')
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Explain the importance of fast language models",
}
],
model="llama-3.3-70b-versatile",
#model = "llama3.2:1b",
)
print(chat_completion.choices[0].message.content)
Fast language models are crucial in natural language processing (NLP) due to their ability to efficiently process and generate human-like language. The importance of fast language models can be seen in several areas:
1. **Real-time Applications**: Fast language models enable real-time applications such as chatbots, virtual assistants, and language translation software. These models can quickly respond to user input, providing a seamless and interactive experience.
2. **Improved User Experience**: Fast language models can generate text, summarize content, and answer questions quickly, making them ideal for applications where speed and efficiency are essential. This leads to a better user experience, as users can quickly obtain the information they need.
3. **Scalability**: Fast language models can handle large volumes of data and scale to meet the demands of big data and high-traffic applications. This makes them suitable for large-scale NLP tasks, such as text classification, sentiment analysis, and named entity recognition.
4. **Low Latency**: Fast language models can reduce latency, which is critical in applications where timely responses are essential, such as in customer service, tech support, or emergency response systems.
5. **Energy Efficiency**: Fast language models can be more energy-efficient, as they require less computational power and memory to process language tasks. This is particularly important for mobile devices, embedded systems, and data centers, where energy consumption is a significant concern.
6. **Edge AI**: Fast language models are essential for edge AI applications, where AI models are deployed on edge devices, such as smartphones, smart home devices, or autonomous vehicles. These models can process language tasks locally, reducing latency and improving real-time decision-making.
7. **Conversational AI**: Fast language models are critical for conversational AI, where models need to quickly understand and respond to user input. This enables more natural and engaging human-computer interactions, such as voice assistants, chatbots, and virtual customer service agents.
8. **Research and Development**: Fast language models can accelerate research and development in NLP, enabling researchers to quickly test and refine their models, and explore new applications and techniques.
Some of the key applications of fast language models include:
* Virtual assistants (e.g., Siri, Alexa, Google Assistant)
* Chatbots and customer service platforms
* Language translation software
* Text summarization and generation tools
* Sentiment analysis and opinion mining
* Named entity recognition and information extraction
* Conversational AI and dialogue systems
To achieve fast language models, researchers and developers employ various techniques, such as:
* Model pruning and quantization
* Knowledge distillation and transfer learning
* Parallelization and distributed computing
* Efficient attention mechanisms and recurrent neural networks
* Optimization of hyperparameters and training procedures
Overall, fast language models are essential for many NLP applications, enabling efficient, scalable, and real-time processing of human language.
%pip install llama-index-program-openai
%pip install llama-index-llms-llama-api
Requirement already satisfied: llama-index-program-openai in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (0.3.1)Note: you may need to restart the kernel to use updated packages.
Requirement already satisfied: llama-index-agent-openai<0.5.0,>=0.4.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-program-openai) (0.4.1)
Requirement already satisfied: llama-index-core<0.13.0,>=0.12.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-program-openai) (0.12.10.post1)
Requirement already satisfied: llama-index-llms-openai<0.4.0,>=0.3.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-program-openai) (0.3.13)
Requirement already satisfied: openai>=1.14.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-agent-openai<0.5.0,>=0.4.0->llama-index-program-openai) (1.58.1)
Requirement already satisfied: PyYAML>=6.0.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (6.0.1)
Requirement already satisfied: SQLAlchemy>=1.4.49 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from SQLAlchemy[asyncio]>=1.4.49->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2.0.36)
Requirement already satisfied: aiohttp<4.0.0,>=3.8.6 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.11.11)
Requirement already satisfied: dataclasses-json in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.6.7)
Requirement already satisfied: deprecated>=1.2.9.3 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.2.15)
Requirement already satisfied: dirtyjson<2.0.0,>=1.0.8 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.0.8)
Requirement already satisfied: filetype<2.0.0,>=1.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.2.0)
Requirement already satisfied: fsspec>=2023.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2024.12.0)
Requirement already satisfied: httpx in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.27.0)
Requirement already satisfied: nest-asyncio<2.0.0,>=1.5.8 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.6.0)
Requirement already satisfied: networkx>=3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.4.2)
Requirement already satisfied: nltk>3.8.1 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.9.1)
Requirement already satisfied: numpy in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.26.4)
Requirement already satisfied: pillow>=9.0.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (10.4.0)
Requirement already satisfied: pydantic>=2.8.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2.10.4)
Requirement already satisfied: requests>=2.31.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2.31.0)
Requirement already satisfied: tenacity!=8.4.0,<10.0.0,>=8.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (8.2.3)
Requirement already satisfied: tiktoken>=0.3.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.7.0)
Requirement already satisfied: tqdm<5.0.0,>=4.66.1 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (4.66.5)
Requirement already satisfied: typing-extensions>=4.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (4.12.2)
Requirement already satisfied: typing-inspect>=0.8.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.9.0)
Requirement already satisfied: wrapt in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.17.0)
Requirement already satisfied: aiohappyeyeballs>=2.3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2.4.4)
Requirement already satisfied: aiosignal>=1.1.2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.3.2)
Requirement already satisfied: attrs>=17.3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.5.0)
Requirement already satisfied: multidict<7.0,>=4.5 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (6.0.4)
Requirement already satisfied: propcache>=0.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.2.1)
Requirement already satisfied: yarl<2.0,>=1.17.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.18.3)
Requirement already satisfied: click in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from nltk>3.8.1->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (8.1.7)
Requirement already satisfied: joblib in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from nltk>3.8.1->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.4.2)
Requirement already satisfied: regex>=2021.8.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from nltk>3.8.1->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2024.5.15)
Requirement already satisfied: anyio<5,>=3.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai>=1.14.0->llama-index-agent-openai<0.5.0,>=0.4.0->llama-index-program-openai) (4.3.0)
Requirement already satisfied: distro<2,>=1.7.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai>=1.14.0->llama-index-agent-openai<0.5.0,>=0.4.0->llama-index-program-openai) (1.9.0)
Requirement already satisfied: jiter<1,>=0.4.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai>=1.14.0->llama-index-agent-openai<0.5.0,>=0.4.0->llama-index-program-openai) (0.8.2)
Requirement already satisfied: sniffio in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai>=1.14.0->llama-index-agent-openai<0.5.0,>=0.4.0->llama-index-program-openai) (1.3.1)
Requirement already satisfied: certifi in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2024.12.14)
Requirement already satisfied: httpcore==1.* in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.0.5)
Requirement already satisfied: idna in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.6)
Requirement already satisfied: h11<0.15,>=0.13 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpcore==1.*->httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.14.0)
Requirement already satisfied: annotated-types>=0.6.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pydantic>=2.8.0->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.6.0)
Requirement already satisfied: pydantic-core==2.27.2 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pydantic>=2.8.0->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2.27.2)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from requests>=2.31.0->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.3.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from requests>=2.31.0->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (2.2.1)
Requirement already satisfied: greenlet!=0.4.17 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from SQLAlchemy>=1.4.49->SQLAlchemy[asyncio]>=1.4.49->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.1.1)
Requirement already satisfied: colorama in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from tqdm<5.0.0,>=4.66.1->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (0.4.6)
Requirement already satisfied: mypy-extensions>=0.3.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from typing-inspect>=0.8.0->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (1.0.0)
Requirement already satisfied: marshmallow<4.0.0,>=3.18.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from dataclasses-json->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (3.25.1)
Requirement already satisfied: packaging>=17.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from marshmallow<4.0.0,>=3.18.0->dataclasses-json->llama-index-core<0.13.0,>=0.12.0->llama-index-program-openai) (24.1)
Collecting llama-index-llms-llama-api
Downloading llama_index_llms_llama_api-0.3.0-py3-none-any.whl.metadata (4.6 kB)
Requirement already satisfied: llama-index-core<0.13.0,>=0.12.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-llms-llama-api) (0.12.10.post1)
Requirement already satisfied: llama-index-llms-openai<0.4.0,>=0.3.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-llms-llama-api) (0.3.13)
Requirement already satisfied: llamaapi<0.2.0,>=0.1.36 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-llms-llama-api) (0.1.36)
Requirement already satisfied: PyYAML>=6.0.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (6.0.1)
Requirement already satisfied: SQLAlchemy>=1.4.49 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from SQLAlchemy[asyncio]>=1.4.49->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2.0.36)
Requirement already satisfied: aiohttp<4.0.0,>=3.8.6 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.11.11)
Requirement already satisfied: dataclasses-json in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.6.7)
Requirement already satisfied: deprecated>=1.2.9.3 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.2.15)
Requirement already satisfied: dirtyjson<2.0.0,>=1.0.8 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.0.8)
Requirement already satisfied: filetype<2.0.0,>=1.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.2.0)
Requirement already satisfied: fsspec>=2023.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2024.12.0)
Requirement already satisfied: httpx in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.27.0)
Requirement already satisfied: nest-asyncio<2.0.0,>=1.5.8 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.6.0)
Requirement already satisfied: networkx>=3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.4.2)
Requirement already satisfied: nltk>3.8.1 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.9.1)
Requirement already satisfied: numpy in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.26.4)
Requirement already satisfied: pillow>=9.0.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (10.4.0)
Requirement already satisfied: pydantic>=2.8.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2.10.4)
Requirement already satisfied: requests>=2.31.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2.31.0)
Requirement already satisfied: tenacity!=8.4.0,<10.0.0,>=8.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (8.2.3)
Requirement already satisfied: tiktoken>=0.3.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.7.0)
Requirement already satisfied: tqdm<5.0.0,>=4.66.1 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (4.66.5)
Requirement already satisfied: typing-extensions>=4.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (4.12.2)
Requirement already satisfied: typing-inspect>=0.8.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.9.0)
Requirement already satisfied: wrapt in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.17.0)
Requirement already satisfied: openai<2.0.0,>=1.58.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from llama-index-llms-openai<0.4.0,>=0.3.0->llama-index-llms-llama-api) (1.58.1)
Requirement already satisfied: aiohappyeyeballs>=2.3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2.4.4)
Requirement already satisfied: aiosignal>=1.1.2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.3.2)
Requirement already satisfied: attrs>=17.3.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.5.0)
Requirement already satisfied: multidict<7.0,>=4.5 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (6.0.4)
Requirement already satisfied: propcache>=0.2.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.2.1)
Requirement already satisfied: yarl<2.0,>=1.17.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from aiohttp<4.0.0,>=3.8.6->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.18.3)
Requirement already satisfied: click in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from nltk>3.8.1->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (8.1.7)
Requirement already satisfied: joblib in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from nltk>3.8.1->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.4.2)
Requirement already satisfied: regex>=2021.8.3 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from nltk>3.8.1->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2024.5.15)
Requirement already satisfied: anyio<5,>=3.5.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai<2.0.0,>=1.58.1->llama-index-llms-openai<0.4.0,>=0.3.0->llama-index-llms-llama-api) (4.3.0)
Requirement already satisfied: distro<2,>=1.7.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai<2.0.0,>=1.58.1->llama-index-llms-openai<0.4.0,>=0.3.0->llama-index-llms-llama-api) (1.9.0)
Requirement already satisfied: jiter<1,>=0.4.0 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai<2.0.0,>=1.58.1->llama-index-llms-openai<0.4.0,>=0.3.0->llama-index-llms-llama-api) (0.8.2)
Requirement already satisfied: sniffio in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from openai<2.0.0,>=1.58.1->llama-index-llms-openai<0.4.0,>=0.3.0->llama-index-llms-llama-api) (1.3.1)
Requirement already satisfied: certifi in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2024.12.14)
Requirement already satisfied: httpcore==1.* in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.0.5)
Requirement already satisfied: idna in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.6)
Requirement already satisfied: h11<0.15,>=0.13 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from httpcore==1.*->httpx->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.14.0)
Requirement already satisfied: annotated-types>=0.6.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pydantic>=2.8.0->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.6.0)
Requirement already satisfied: pydantic-core==2.27.2 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from pydantic>=2.8.0->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2.27.2)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from requests>=2.31.0->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.3.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from requests>=2.31.0->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (2.2.1)
Requirement already satisfied: greenlet!=0.4.17 in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from SQLAlchemy>=1.4.49->SQLAlchemy[asyncio]>=1.4.49->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.1.1)
Requirement already satisfied: colorama in c:\users\nboateng\appdata\roaming\python\python312\site-packages (from tqdm<5.0.0,>=4.66.1->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (0.4.6)
Requirement already satisfied: mypy-extensions>=0.3.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from typing-inspect>=0.8.0->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (1.0.0)
Requirement already satisfied: marshmallow<4.0.0,>=3.18.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from dataclasses-json->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (3.25.1)
Requirement already satisfied: packaging>=17.0 in c:\users\nboateng\appdata\local\anaconda3\lib\site-packages (from marshmallow<4.0.0,>=3.18.0->dataclasses-json->llama-index-core<0.13.0,>=0.12.0->llama-index-llms-llama-api) (24.1)
Downloading llama_index_llms_llama_api-0.3.0-py3-none-any.whl (4.7 kB)
Installing collected packages: llama-index-llms-llama-api
Successfully installed llama-index-llms-llama-api-0.3.0
Note: you may need to restart the kernel to use updated packages.
LitGPT
LitGPT is a state-of-the-art language model that leverages cutting-edge algorithms and training methodologies to generate highly coherent, context-aware, and human-like text. Developed as a successor to earlier generations of AI language models, LitGPT pushes the boundaries of creativity, comprehension, and usability.
Unlike traditional models, LitGPT focuses on delivering:
Enhanced Contextual Understanding: With its ability to retain and interpret nuanced context over long conversations or documents, LitGPT offers more accurate and relevant responses.
Fine-Tuning Options: It allows developers to customize the model for specific industries, use cases, or unique datasets.
Efficiency and Scalability: Built with optimized architectures, LitGPT can handle high-demand environments without compromising speed or quality.
Step 1: Create a virtual environment on ubuntu linux distribution
python3 -m venv local_llm
Step 2: Activate the virtual environment
source local_llm/bin/activate
Step 3: Upgrade pip within the virtual environment
pip install --upgrade pip
Step 4: Install packages as needed
pip install 'litgpt[all]'
#!pip install 'litgpt[all]'
from litgpt import LLM
llm = LLM.load("microsoft/phi-2")
text = llm.generate("Fix the spelling: Every fall, the familly goes to the mountains.")
print(text)
# Corrected Sentence: Every fall, the family goes to the mountains.