Hands On Web Scraping in Python
Sources of data for data science projects include SQL/NoSQL databases,cloud enviroments and data stored on local machines. There are times we also extract data such reviews from online sources like various web pages. In this postI would share some experiences with extracting text data and subsequntly anlyzing with natural language processing techniques. We can start by requesting the content of the first web page: here. As follows :
The steps to extracting the data from the first page involves:
-
Import the get() function from the requests module then assign the address of the web page to a variable named url.
-
Request from the server the content of the url or web page by using get(), and store the server’s response in the variable response.
-
We then print a little part of the content of the response by accessing its .text attribute.
-
BeautifulSoup library allows you to parse the HTML source code from the get() function.
-
Timeout request parameter is set to 5 seconds to prevent request from waiting for a response indefinately.
from requests import get
import requests
import numpy as np
import pandas as pd
from datetime import datetime
from dateutil.parser import parse
import re
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from bs4 import BeautifulSoup
%matplotlib inline
url="https://www.indeed.com/cmp/Fiat-Chrysler-Automobiles/reviews"
# fetch the content from url and timeout to 5 seconds
response = requests.get(url, timeout=5)
print(response.text[:500])
# parse html
html_soup = BeautifulSoup(response.text, 'html.parser')
type(html_soup)
<!doctype html><html>
<head>
<title>Working at Fiat Chrysler Automobiles: 2,026 Reviews | Indeed.com</title>
<meta http-equiv="content-type" content="text/html;charset=UTF-8"/><meta name="description" content="2,026 reviews from Fiat Chrysler Automobiles employees about Fiat Chrysler Automobiles culture, salaries, benefits, work-life balance, management, job security, and more on Indeed.com."/><meta name="viewport" content="width = device-width, initial-scale=1.0, maximum-scale=1.0, user-sca
bs4.BeautifulSoup
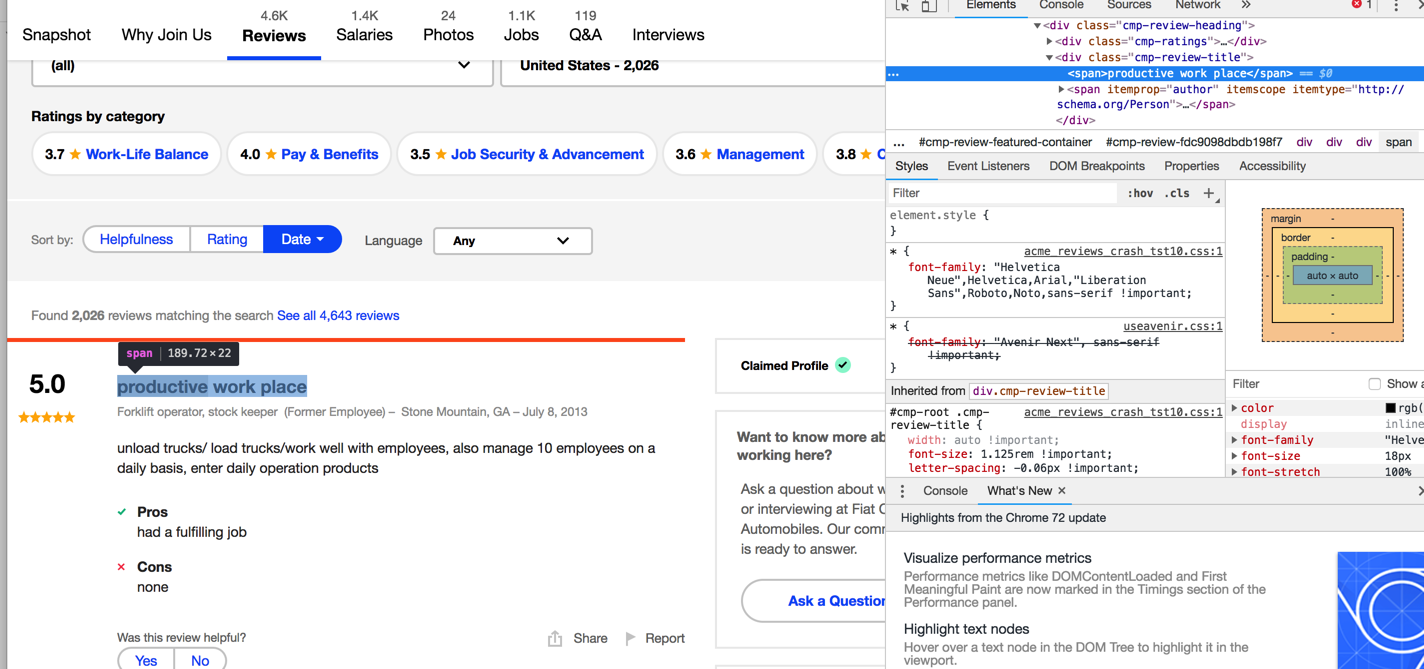
We can create containers to extract the date,the reviews,title,location,job decription and the status of employment at the time of review. When you right-click on an element in Chrome and select ‘Inspect’, you can see the source code in the right panel. For example, if we right click on the title of the first review on the first page for FCA indeed reviews is below: The find_all function with a specified attrs which can be obtained from the html structure allows us to collect the specific data of interest on a web page.
from IPython.display import Image
Image(filename='/indeedfca.png')
date_containers = html_soup.find_all('span', attrs={'class':'cmp-review-date-created'})
print(date_containers)
text_containers = html_soup.find_all('span', attrs={'class':'cmp-review-text'})
print(text_containers[1].text)
title_containers = html_soup.find_all('div', attrs={'class':'cmp-review-title'})
print(title_containers[1].text)
location_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer-job-location'})
print(location_containers[1].text)
job_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer'})
jobstatus_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer-job-title'})
print(jobstatus_containers[1].text[-21:-5])
print(job_containers[1].text)
#star_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer-job-title'})
rating_containers = html_soup.find_all('div', attrs={'class':'cmp-ratingNumber'})
[<span class="cmp-review-date-created">July 8, 2013</span>, <span class="cmp-review-date-created">March 12, 2019</span>, <span class="cmp-review-date-created">March 10, 2019</span>, <span class="cmp-review-date-created">March 7, 2019</span>, <span class="cmp-review-date-created">March 6, 2019</span>, <span class="cmp-review-date-created">March 5, 2019</span>, <span class="cmp-review-date-created">March 4, 2019</span>, <span class="cmp-review-date-created">February 28, 2019</span>, <span class="cmp-review-date-created">February 26, 2019</span>, <span class="cmp-review-date-created">February 26, 2019</span>, <span class="cmp-review-date-created">February 26, 2019</span>, <span class="cmp-review-date-created">February 24, 2019</span>, <span class="cmp-review-date-created">February 24, 2019</span>, <span class="cmp-review-date-created">February 20, 2019</span>, <span class="cmp-review-date-created">February 20, 2019</span>, <span class="cmp-review-date-created">February 20, 2019</span>, <span class="cmp-review-date-created">February 19, 2019</span>, <span class="cmp-review-date-created">February 19, 2019</span>, <span class="cmp-review-date-created">February 17, 2019</span>, <span class="cmp-review-date-created">February 15, 2019</span>, <span class="cmp-review-date-created">February 14, 2019</span>]
This company keeps lowering times to screw over techs any chance possible. This is why there is a huge shortage of technicians. The Flat rate system is failing 80% of good techs and the market will continue to die off as the manufacturer continues to take advantage of technicians.
Techs stay far away
Albany, NY
Current Employee
Automotive Master Technician
job_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer'})
job_containers[1].text
'Automotive Master Technician'
len(date_containers)
21
range(len(text_containers))
range(0, 21)
Putting all the containers from the first page together here.
date_container=[]
text_container=[]
title_container=[]
location_container=[]
job_container=[]
jobstatus_container=[]
rating_container=[]
for i in range(len(text_containers)):
date_container.append(date_containers[i].text)
text_container.append(text_containers[i].text)
title_container.append(title_containers[i].text)
location_container.append(location_containers[i].text)
job_container.append(job_containers[i].text)
jobstatus_container.append(jobstatus_containers[i].text[-21:-5])
rating_container.append(rating_containers[i].text)
The containers from the first page can all be combined into a pandas dataframe which would be suitable for the analysis we would like to perform on it later after all the pages have been extracted.
z=[len(date_container),len(text_container),len(title_container),len(location_container),
len(job_container),len(jobstatus_container)]
df = pd.DataFrame({ 'Date' : date_container,
'Rating' : rating_container,
'Title' : title_container,
'Location' : location_container,
'Job' : job_container,
'Jobstatus' : jobstatus_container,
'Text' : text_container})
#Remove all parenthesis from Jobstatus column
df['Jobstatus']=df['Jobstatus'].str.replace("(","")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 21 entries, 0 to 20
Data columns (total 7 columns):
Date 21 non-null object
Rating 21 non-null object
Title 21 non-null object
Location 21 non-null object
Job 21 non-null object
Jobstatus 21 non-null object
Text 21 non-null object
dtypes: object(7)
memory usage: 1.2+ KB
The data from the first page represented in a dataframe is displayed below.
df.head()
| Date | Rating | Title | Location | Job | Jobstatus | Text | |
|---|---|---|---|---|---|---|---|
| 0 | July 8, 2013 | 5.0 | productive work place | Stone Mountain, GA | Forklift operator, stock keeper | Former Employee | unload trucks/ load trucks/work well with empl... |
| 1 | March 12, 2019 | 1.0 | Techs stay far away | Albany, NY | Automotive Master Technician | Current Employee | This company keeps lowering times to screw ove... |
| 2 | March 10, 2019 | 4.0 | Decent place to work at | Warren, MI | Hi-Lo Driver | Current Employee | Working at Fiat Chrysler it not bad just long ... |
| 3 | March 7, 2019 | 2.0 | Fca | Belvidere, IL | Production Supervisor | Current Employee | Fight with operators who have a union that pro... |
| 4 | March 6, 2019 | 4.0 | very fast pace,lots of noise but benefits made... | Warren, MI | Assembly Line Worker | Former Employee | A typical day at FCA was you come in and o to ... |
We can create a list to store all website urls from which we would extract the text reviews. From the structure of the urls, every preceeding url differs from the next by a multiple 20. With this in mind we can can generate all urls,store in a list and apply a function to extract the needed information from each url.
url="https://www.indeed.com/cmp/Fiat-Chrysler-Automobiles/reviews"
v='https://www.indeed.com/cmp/Fiat-Chrysler-Automobiles/reviews?start='
w=[]
for i in np.arange(20,1980,20):
w.append(v+str(i))
url=[url]
url.append(w)
url.extend(w)
Function to extract information from the first page
The steps we undertook above to extract the first page contents can now be placed inside a function webscrap which later can be called over the other urls.
def webscrap (url):
response = get(url)
html_soup = BeautifulSoup(response.text, 'html.parser')
date_containers = html_soup.find_all('span', attrs={'class':'cmp-review-date-created'})
text_containers = html_soup.find_all('span', attrs={'class':'cmp-review-text'})
title_containers = html_soup.find_all('div', attrs={'class':'cmp-review-title'})
location_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer-job-location'})
job_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer'})
jobstatus_containers = html_soup.find_all('span', attrs={'class':'cmp-reviewer-job-title'})
rating_containers = html_soup.find_all('div', attrs={'class':'cmp-ratingNumber'})
z=[len(date_containers),len(text_containers),len(title_containers),len(location_containers),
len(job_containers),len(jobstatus_containers)]
#min(z)
z2=np.amin(z)
date_container=[]
text_container=[]
title_container=[]
location_container=[]
job_container=[]
jobstatus_container=[]
rating_container=[]
for i in range(z2):
date_container.append(date_containers[i].text)
text_container.append(text_containers[i].text)
title_container.append(title_containers[i].text)
location_container.append(location_containers[i].text)
job_container.append(job_containers[i].text)
jobstatus_container.append(jobstatus_containers[i].text[-21:-5])
rating_container.append(rating_containers[i].text)
# store extracted information in a dataframe
df = pd.DataFrame({ 'Date' : date_container,
'Rating' : rating_container,
'Title' : title_container,
'Location' : location_container,
' Job' : job_container,
'Jobstatus' : jobstatus_container,
'Text' : text_container})
#Remove all parenthesis from Jobstatus column
df['Jobstatus']=df['Jobstatus'].str.replace("(","")
# change the type of Date from object to datetime column for plotting
df['Date'] = pd.to_datetime(df['Date'])
return df;
Repeat function over first webpages
url="https://www.indeed.com/cmp/Fiat-Chrysler-Automobiles/reviews"
webscrap (url ).head(4)
| Date | Rating | Title | Location | Job | Jobstatus | Text | |
|---|---|---|---|---|---|---|---|
| 0 | 2013-07-08 | 5.0 | productive work place | Stone Mountain, GA | Forklift operator, stock keeper | Former Employee | unload trucks/ load trucks/work well with empl... |
| 1 | 2019-03-12 | 1.0 | Techs stay far away | Albany, NY | Automotive Master Technician | Current Employee | This company keeps lowering times to screw ove... |
| 2 | 2019-03-10 | 4.0 | Decent place to work at | Warren, MI | Hi-Lo Driver | Current Employee | Working at Fiat Chrysler it not bad just long ... |
| 3 | 2019-03-07 | 2.0 | Fca | Belvidere, IL | Production Supervisor | Current Employee | Fight with operators who have a union that pro... |
Repeat function over all webpages
The function webscrap, we just created can be used to extract the needed data from the second to the last page url with the help of the map function which works similarly like creating a for loop.
pages_2last=list(map(webscrap,w))
Concatenate all pages extracted into one data frame
page_1=webscrap(url)
#pd.concat([pages_2last,page_1])
AllData=pd.Series.append(page_1,pages_2last)
AllData=pd.DataFrame(AllData)
AllData.head()
| Date | Rating | Title | Location | Job | Jobstatus | Text | |
|---|---|---|---|---|---|---|---|
| 0 | 2013-07-08 | 5.0 | productive work place | Stone Mountain, GA | Forklift operator, stock keeper | Former Employee | unload trucks/ load trucks/work well with empl... |
| 1 | 2019-03-12 | 1.0 | Techs stay far away | Albany, NY | Automotive Master Technician | Current Employee | This company keeps lowering times to screw ove... |
| 2 | 2019-03-10 | 4.0 | Decent place to work at | Warren, MI | Hi-Lo Driver | Current Employee | Working at Fiat Chrysler it not bad just long ... |
| 3 | 2019-03-07 | 2.0 | Fca | Belvidere, IL | Production Supervisor | Current Employee | Fight with operators who have a union that pro... |
| 4 | 2019-03-06 | 4.0 | very fast pace,lots of noise but benefits made... | Warren, MI | Assembly Line Worker | Former Employee | A typical day at FCA was you come in and o to ... |
Write The File to excel
We can write the dataframe to file ,so we wouldn’t have to repeat the extraction phase every time we need to use this data.The data can be saved as .xlsx or alternatively as a .csv format.
# Create a Pandas dataframe from the data.
df = AllData
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('/AllData.xlsx', engine='xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='Sheet1')
# Close the Pandas Excel writer and output the Excel file.
writer.save()
Write to a csv File
# Create a Pandas dataframe from the data.
pd.DataFrame.to_csv(AllData,'/AllData.csv')
We can generate random user agent to deal with websites that require browser information from a user agent inorder to show you content.
# library to generate user agent
from user_agent import generate_user_agent
# generate a user agent
headers = {'User-Agent': generate_user_agent(device_type="desktop", os=('mac', 'linux'))}